一、为什么需要分布式锁
单机锁: 多个线程同时改变一个变量时,需要对变量或者代码块做同步从而保证串行修改变量.
多机系统: 存在多机器多请求同时对同一个共享资源进行修改,如果不加以限制,将导致数据错乱和数据不一致性. 比如: 库存超卖、抽奖多发、券多发放、订单重复提交…
二、常见的分布式锁
|
实现方式 |
优点 |
缺点 |
应用场景 |
|
MySQL数据库表 |
易于理解/易于实现 |
容易出现单点故障、死锁性能低/可靠性低 |
适用于并发量低、 性能要求低的场景 |
|
Redis分布式锁 |
性能高/易于实现可跨集群部署,无单点故障 |
锁失效时间的控制不稳定稳定性低于 ZooKeeper |
适用于高并发、高性能场景 |
|
ZooKeeper 分布式锁 |
无单点故障/可靠性高不可重入/无死锁问题 |
实现复杂性能低于缓存分布式锁 |
适用于大部分分布式场景, 除对性能要求极高的场景 |
三、 用Redis实现一个分布式锁
3.1 SETNX
SET lock 1 NX
String buyTicket() {
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1");
if (lock) {
try {
int stockNum = byTicketMapper.selectStockNum();
if (stockNum > 0) {
//TODO by ticket process....
byTicketMapper.reduceStock();
return "SUCCESS";
}
return "FAILED";
}finally {
redisTemplate.delete("lock");
}
}
return "OOPS...PLEASE TRY LATTER";
}
Java代码很容易看出, 假如执行了加锁后程序出现宕机, 执行不到finally语句块里的解锁, 就出会有死锁问题. 为了解决死锁, 很容易就想到给锁设置一个过期时间.
3.2 设置锁过期时间和唯一ID
设置key时同时设置过期时间:
SET lock 1 NX EX 30
Java代码:
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", "1", Duration.ofSeconds(10L));
但这会导致更严重的错删锁问题, 比如某个线程1加锁后, 执行业务逻辑比较慢, 锁过期自动释放了, 此时线程2竞争加锁成功, 而线程1执行了删除锁, 以此类推, 相当于锁失效.
改进: 设置线程UUID, 并且用lua脚本保证GET和DEL原子性操作, 防止删错key
String buyTicket() {
String uuid = UUID.randomUUID().toString();
Boolean lock = redisTemplate.opsForValue().setIfAbsent("lock", uuid, Duration.ofSeconds(10L));
if (lock) {
try {
int stockNum = byTicketMapper.selectStockNum();
if (stockNum > 0) {
//TODO by ticket process....
byTicketMapper.reduceStock();
return "SUCCESS";
}
return "FAILED";
} finally {
String script = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
this.redisTemplate.execute(new DefaultRedisScript(script), Arrays.asList("lock"), uuid);
}
}
return "OOPS...PLEASE TRY LATTER";
}
看起来好像还不错, 但是依然有过期时间无法完全匹配实际需求的问题:
太短 -> 锁失效无法保证程序正确处理业务
太长 -> 异常流程过度占有锁导致资源浪费
有更好的解决方案吗? 比如开启一个后台线程, 定时检查主线程是否持有锁(即未完成操作资源), 给它自动延长锁过期时间. 幸运的javaer 已经Redisson库封装好了这些操作.
3.3 Redisson
看门狗机制: 加一个后台线程定时检查锁,自动续过期时间
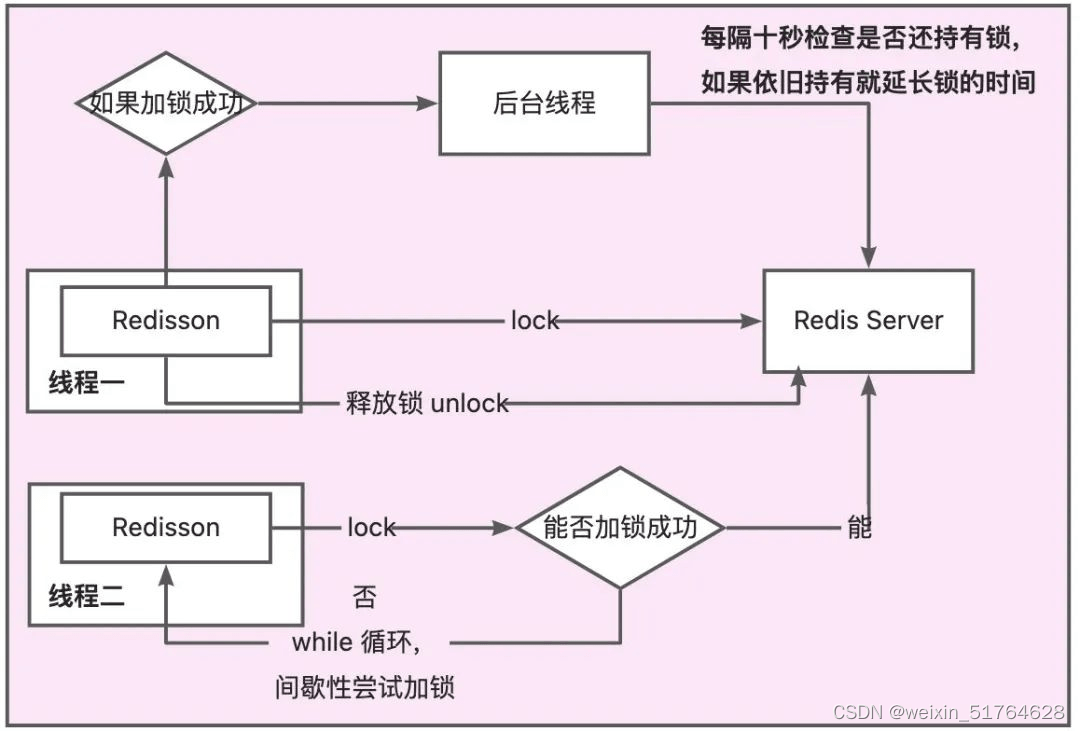
Java代码
String buyTicket() {
RLock lock = redissonClient.getLock("lock");
try {
if (lock.tryLock(30,TimeUnit.SECONDS)) {
int stockNum = byTicketMapper.selectStockNum();
if (stockNum > 0) {
//TODO by ticket process....
byTicketMapper.reduceStock();
return "SUCCESS";
}
return "FAILED";
}
}catch (InterruptedException e){
log.error("Try Lock Error:{}",e.getMessage());
}finally {
lock.unlock();
}
return "OOPS...PLEASE TRY LATTER";
}
对于单机版的redis至此已经是很好的方案了, 然而现实中大多数使用的是集群redis…
四、 主从同步对分布式锁的影响
高并发场景主从切换锁失效: 试想一下这样的场景, 主节点加锁成功, 没有同步到从节点时主节点宕机, 此时从节点选举出新的主节点, 它就丢失了还没同步的锁, 此时其他客户端向新的主节点请求加锁会成功, 导致冲突.
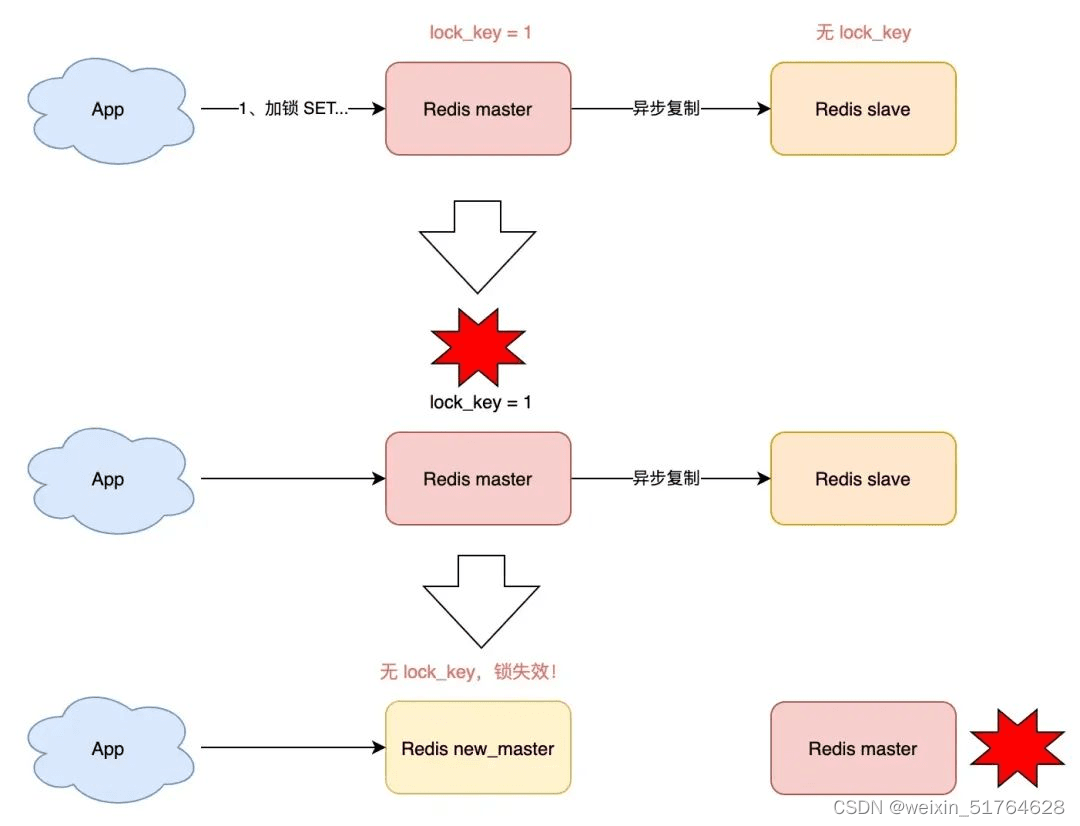
4.1 Redlock
Redlock 的方案官网解释: 既然主从架构有问题, 那就部署多个主库实例.
Redlock整体流程:
- 客户端在多个 Redis 实例上申请加锁
- 必须保证大多数节点(超过半数)加锁成功
- 大多数节点加锁的总耗时,要小于锁设置的过期时间
- 释放锁,要向全部节点发起释放锁请求
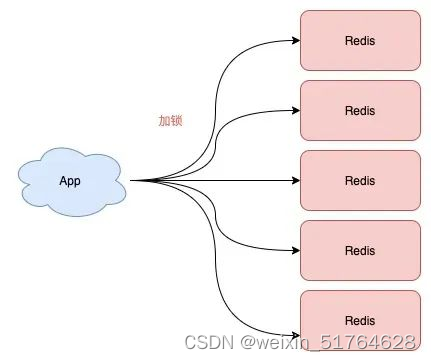
疑问:
1 ) 假如有3个客户端竞争同一资源, 向5个Redis请求获取锁, 容易出现没有获胜者的情况.
-> redis官方: 多路复用 以及 没有获得过半数锁的客户端尽快释放锁
2) 某个主节点宕机时可能出现锁安全性问题. 比如: 当Redis持久化策略为AOF使用appendfsync=everysec即每秒fsync一次, 故障时会丢失1秒的数据, 也就是丢锁. 当该节点恢复时, 其他客户端来获取锁成功
-> redis官方: 在崩溃后使实例不可用, 至少比最大 TTL多一点, 保证崩溃时的锁在所有节点都自动失效. [损失了可用性]
RedLock的争论:
针对RedLock的方案, 业界大佬Martin Kleppmann专门写过一篇文章分析它的效率, 正确性和NPC问题 , redis的作者也一一反驳, 有兴趣可以看文章末尾参考资料.
NPC问题:
Clock Drift时钟漂移
-> redis作者: 与锁的自动释放时间相比,误差幅度很小
Network Delay网络延迟
Process Pause进程暂停(GC)
-> redis作者: 第3步已经考虑了以上问题, 当出现 加锁总耗时 > 锁过期时间 就会认为加锁失败, 而在步骤3之后出现GC或ND问题, 其他锁服务比如zookeeper也这样.
通过以上争论, 我们看到redlock确实存在一些缺点:
1) 性能折损, 且无法做到100%安全的分布式锁
2) 不能横向扩容: 如果要提升高可用, 只能增加更多单节点, 每个单节点不能再加从节点
4.2 Fencing Token
针对主从架构下的分布式锁, 前面提到的Martin Kleppmann, 在它的文章里提出了”fencing token”的解决方案:
-
客户端在获取锁时,锁服务可以提供一个「递增」的 token
-
客户端拿着这个 token 去操作共享资源
-
共享资源可以根据 token 拒绝「后来者」的请求
这个方案要求共享资源具备”互斥”能力, 而且在分布式环境下做严格自增的token无疑也是个难题.
有没有其他方案呢, 在找资料的过程中, 我发现Redisson较新的版本(我用的是3.25.0)提供了FencedLock.
4.3 FencedLock
它的底层获取锁的同时, 使用 incr 命令从redis获取自增的token:
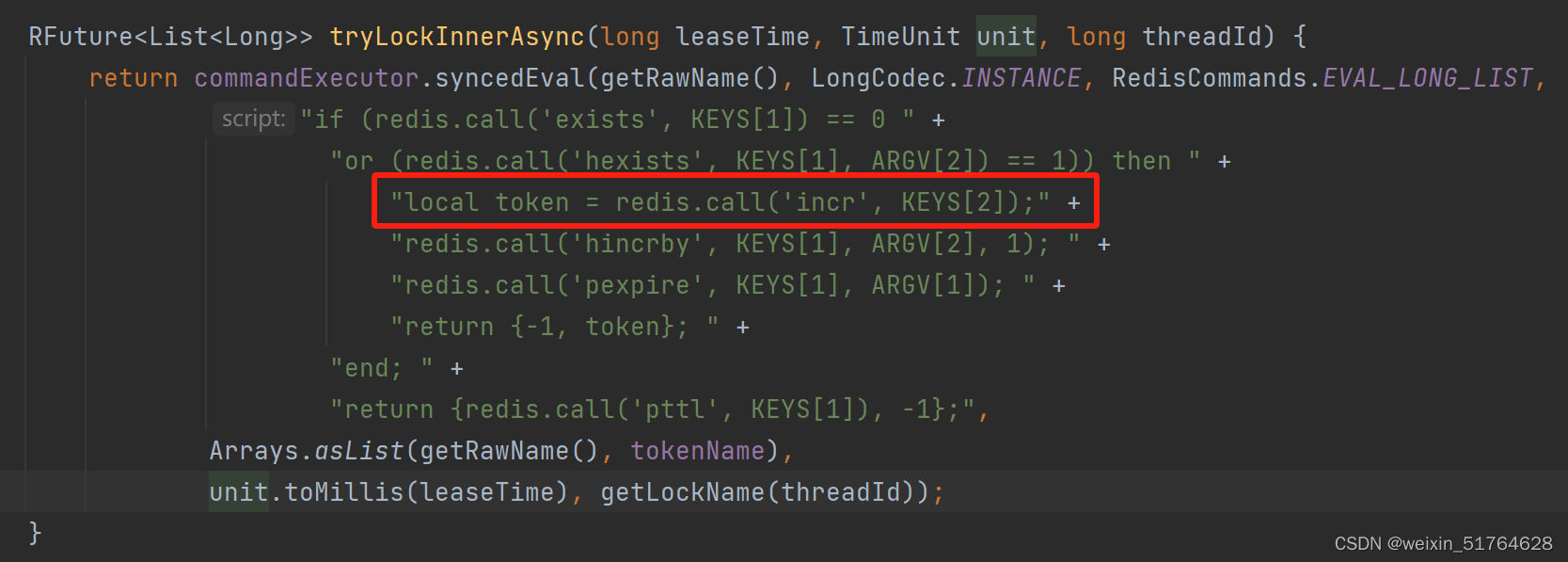
但是在redis集群环境下, 这样使用incr会有可靠性问题. 当多个客户端同时调用incr命令时,可能会出现并发冲突,导致数据不一致.
虽然redisson的官方文档说RedLock已弃用,推荐使用Lock or FencedLock, 但如前述我觉得上述FencedLock会有可靠性问题. (如果大佬们有其他见解, 请赐教, 感激~)
4.4 兜底锁
对安全性要求比较高的场景, 也许我们可以参考fencing token的思路在资源层再做一个兜底锁, 比如MySQL:
在操作资源前先标记token, 再(检查+修改)共享资源
UPDATE
table T
SET
val = $new_val
WHERE
id = $id AND current_token = $token_value;
两种思路结合我们就拥有了一个更安全可靠的分布式锁体系:
- redis分布式锁: 作用于上层, 完成了大多数”互斥”, 把大部分请求挡在上层, 减轻了操作资源层的压力.
- MySQL兜底锁: 通过版本号或者插入锁的方式实现”互斥”, 避免极端情况下的并发冲突, 由于上层已经挡住了大部分请求, MySQL锁也能很好的避开它本身的缺点.
五、总结
1) 没有一把完美的分布式锁, 在设计分布式锁的时候, 需要多角度考虑它是否满足了以下特性:
- 独占排他互斥
- 防死锁
- 保证原子性
- 正确性
- 可重入
- 容错分布式
2) 如果是要求数据绝对正确的业务, 资源层要做好兜底。
到此这篇关于Redis分布式锁及安全问题解决的文章就介绍到这了,更多相关Redis分布式锁内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

