elk是我们常用的日志查询系统,使用高效的查询方法能使我们快速定位日志以及解决问题;
精准模糊匹配关键字
类似 mysql:like %seven%
在搜索框对关键字添加双引号即可 :
eg:
“seven”

多个关键字同时模糊匹配
多个关键词双引号后使用and连接
eg:
"0eca9570-6441-4e2e-9d2c-09eb5764506b" and "夏艺桐"

更多kibana查询语法
当然还有更多的查询姿势,这里不一一举例,他们的使用方法如下:
1、要搜索一个确切的字符串,即精确搜索,需要使用双引号引起来:path:”/app/logs/nginx/access.log”
2、如果不带引号,将会匹配每个单词:uid token
3、模糊搜索:path:”/app/~
4、* 匹配0到多个字符:*oken
5、? 匹配单个字符 : tok?n
6、+:搜索结果中必须包含此项 -:不能含有此项 什么都没有则可有可无: +token -appVersion appCode
7、运算符AND/OR/NOT必须大写:token AND uid ;token OR uid;NOT uid
8、允许一个字段值在某个区间([] 包含该值,{}不包含):@version:[1 TO 3]
9、组合查询:(uid OR token) AND version
10、转义特殊字符 + – && || ! ( ) { } [ ] ^ ” ~ * ? : 转义特殊字符只需在字符前加上符号
11、分组(firstname:H* OR age:20) AND state:KS 先查询名字H开头年龄或者是20的结果,然后再与国家是KS的结合
12、firstname:(+H* -He*) 搜索firstname字段里H开头的结果,并且排除firstname里He开头的结果
13.查询一,xxx:[1 TO *]
其他
在ekl之外,我也使用过一款开源的,开箱即用的日志组建:
https://gitee.com/frankchenlong/plumelog/tree/master/
它的底层也是通过es来存储日志,总体使用感受是,很轻量级,但是功能齐全,用户体验比elk好上不少,最喜欢他的功能是:
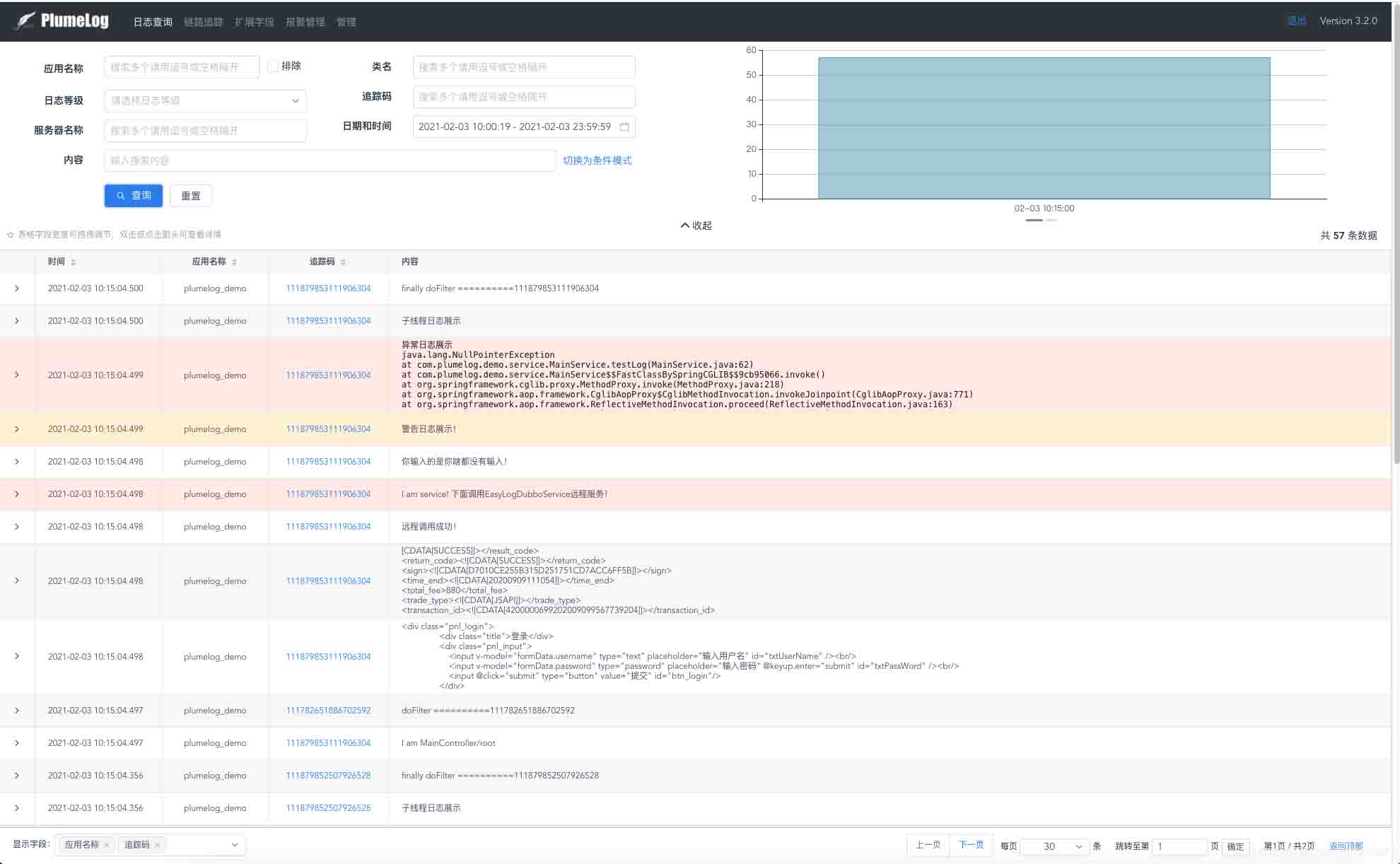
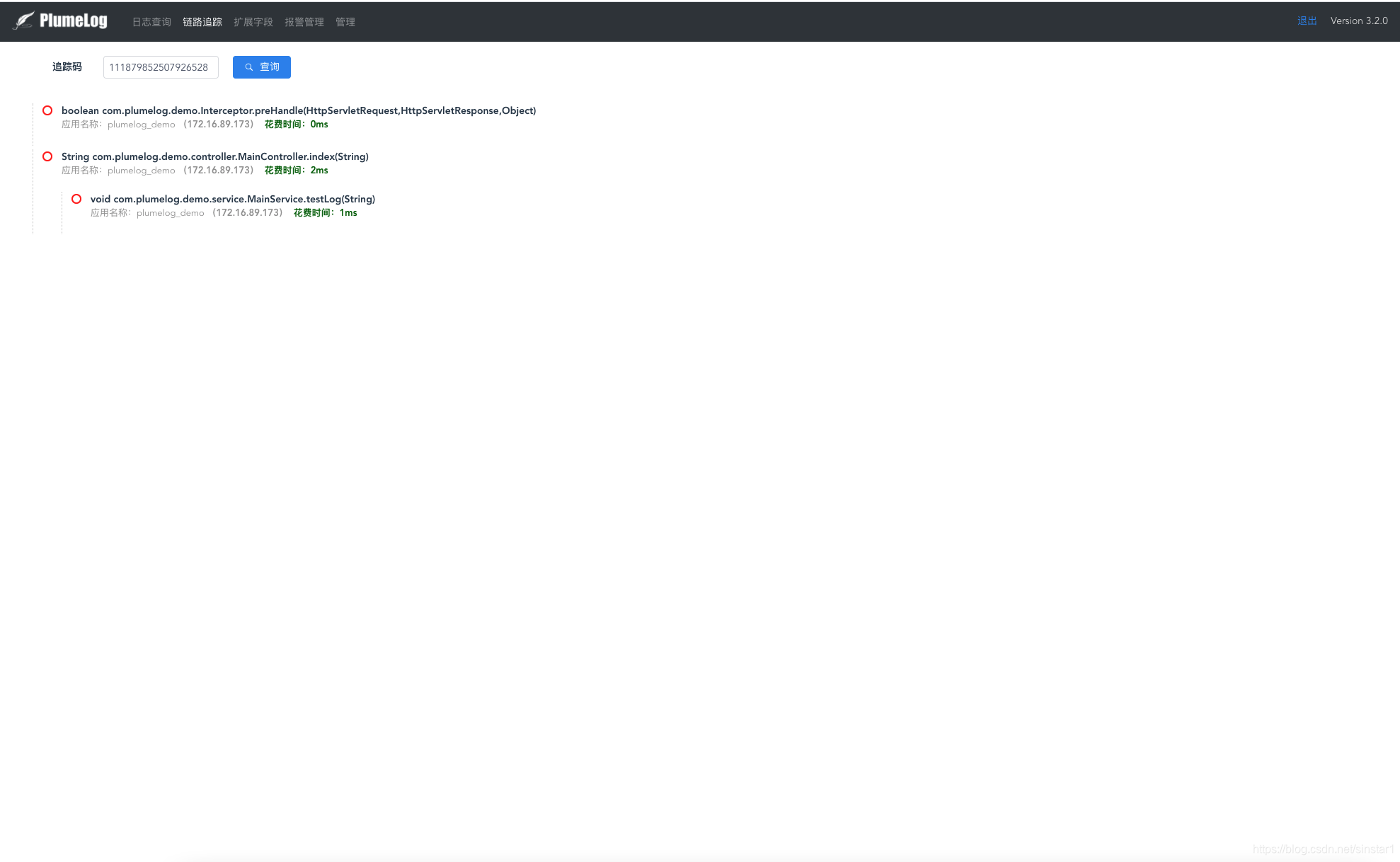
- 链路追踪,在微服务架构下,能帮我快速定位哪个服务耗时较长
- 通过追踪码和ip,可以分机器,分业务的查询此次请求日志
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持IT俱乐部。

