前言
partition by与group by都是对表中的某维度进行分组。不同的是partition by返回的是分组后的每一条记录,不改变表中数据行数,后续可以做排序、topN等操作;而 group by返回的是分组的聚合值,例如max、sum、avg等值。`
一、窗口函数
1.基本语法:
over ( partition by order by desc) as "rank_col"
执行顺序为:
1、根据 进行分组操作(partition by),得到分组结果(中间表);
2、对结果的每个分组进行组内(desc降序)排序:order by (中间表);
3、将窗口函数用于上述结果的每个分组(over):增加组内排序序号列”rank_col”。窗口函数包括rank(),dense_rank(),row_number()等。
以上过程生成了一个分组、组内排序、增加组内排序序号列的结果。
rank()函数:如果有并列名次的行,会占用下一个名次的位置。比如正常排名是1,2,3,4,但是现在前3名是并列的名次,所以结果是:1,1,1,4.
dense_rank()函数:如果有并列的名次,它不会占用下一个名次的位置,比如比如正常排名是1,2,3,4,但是现在前3名是并列的名次,所以结果是:1,1,1,2.
row_number()函数:不考虑并列的情况,比如前3名是并列的名次,排名是正常的1,2,3,4.
2.示例
[LC185]. 部门工资前三高的所有员工

公司的主管们感兴趣的是公司每个部门中谁赚的钱最多。一个部门的 高收入者 是指一个员工的工资在该部门的 不同 工资中 排名前三 。编写解决方案,找出每个部门中 收入高的员工
输出格式要求如下:

分析:
题目要求是找出 每个部门中 排名前三的员工(partition by 部门),且相同收入水平并列、不占用后续排序位置(dense_rank())。
写sql前,最好把过程先想清楚,把每个中间子表想清楚,把重要的中间子表可以查出来看看,最后再完善代码,且不要上来就搞代码。思路如下:
1、先把最核心的计算写出来
分组以及组内排序:
select *, dense_rank() over(partition by departmentId order by salary desc) as rank_col from Employee
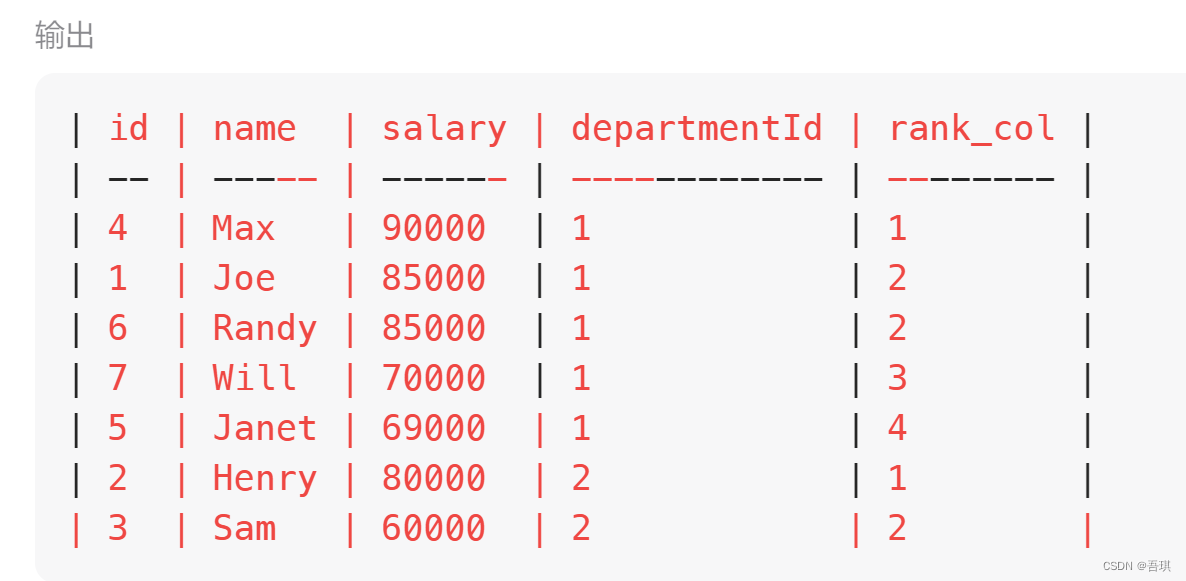
按分组排序输出了,且增加了排序列rank_col,但是没有限制前三。
2、从上面的结果中,取每组的前三
把上面的结果当作子表查询
select * from( select *, dense_rank() over(partition by departmentId order by salary desc) as rank_col from Employee ) a where a.rank_col

到这里,核心的计算算是完成了,实现了 每个部门中排名前三,且相同收入水平并列、不占用后续排序位置的要求。下一步,要按照规定格式输出。
3、按要求格式输出
继续把上面的结果当作子表查询
select d.name Department, b.name Employee,b.salary Salary from (select * from( select *, dense_rank() over(partition by departmentId order by salary desc) as rank_col from Employee ) a where a.rank_col
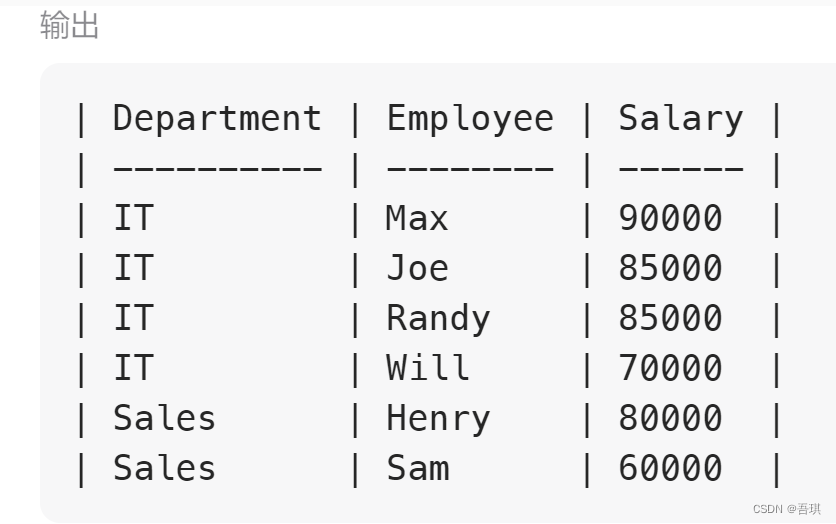
输出正确,测试通过。
4、sql优化
分组以及组内排序后,直接join,节省一个中间子表
select d.name Department, a.name Employee,a.salary Salary from (select *, dense_rank() over(partition by departmentId order by salary desc) as "rank" from Employee ) a left join Department d on a.departmentId = d.id where a.rank <4
输出正确,测试通过。
到此这篇关于SQL窗口函数之partition by的使用的文章就介绍到这了,更多相关SQL partition by内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

