一、Explain
1.1 explain作用
在sql语句前添加explain,作用是查看mysql对这条sql的执行计划信息。
思考:MYSQL执行SQL语句时一定按这个执行计划执行么?
1.2 explain列说明
在一条简单SQL前面添加explain查看有哪些列,如下:

id
每个select对应一个id值,其值是按 select 出现的顺序增长的。
注:id值越大执行优先级越高,id相同则从上往下执行,id为NULL最后执行
select_type
每个select对应一个select_type,表示select的复杂度,有:
SIMPLE:简单查询。查询不包含子查询和union,如上图
PRIMARY:对于包含UNION、UNION ALL或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的那个查询的select_type值就是PRIMARY
SUBQUERY:包含在 select 中的子查询(不在 from 子句中)
DERIVED:对于包含‘派生表’的查询
UNION:在 union 中的第二个和随后的 select
table
这一列表示 explain 的一行正在访问哪个表。
当 from 子句中有子查询时,table列是 格式,表示当前查询依赖 id=N 的查询,于是先执行 id=N 的查 询。
当有 union 时,UNION RESULT 的 table 列的值为,1和2表示参与 union 的 select 行id。
partiitons
匹配的分区信息
type
这一列表示关联类型或访问类型
效率从最优到最差分别为:system > const > eq_ref > ref > range > index > ALL
SQL性能优化的目标:至少要达到range级别,要求是ref级别,最好是consts级别。
system:当表中只有一条记录并且该表使用的存储引擎的统计数据都是精确地,表最多有一个匹配行,读取1次,速度比较快。
const:system是 const的特例,表里只有一条元组匹配时为system
eq_ref:primary key 或 unique key 索引的所有部分被连接使用 ,最多只会返回一条符合条件的记录。
ref:相比 eq_ref,不使用唯一索引,而是使用普通索引或者唯一性索引的部分前缀,索引要和某个值相比较,可能会 找到多个符合条件的行。
range:用索引获取某些范围区间的记录。
select_type
每个select对应一个select_type,表示select的复杂度
SIMPLE:简单查询。查询不包含子查询和union,如上图
PRIMARY:对于包含UNION、UNION ALL或者子查询的大查询来说,它是由几个小查询组成的,其中最左边的那个查询的select_type值就是PRIMARY
SUBQUERY:包含在 select 中的子查询(不在 from 子句中)
DERIVED:对于包含‘派生表’的查询
UNION:在 union 中的第二个和随后的 select
possible_keys
标识某个表查询时可能使用哪些索引来查找。
key
实际使用哪个索引。
当possible_keys有值,而key没有值时,可能是因为表数据很少,mysql认为没有必要走索引,直接全表查询了。
当possible_keys为null时,可根据实际情况在where条件中添加索引来提升查询效率。
key_len(key_len值计算)
实际使用到的索引的字节数,帮我们检查是否充分利用上了索引,对于联合索引有一定的参考意义。
比如有列n和address的联合索引(表my_datas字段有id, n, address 和 time)
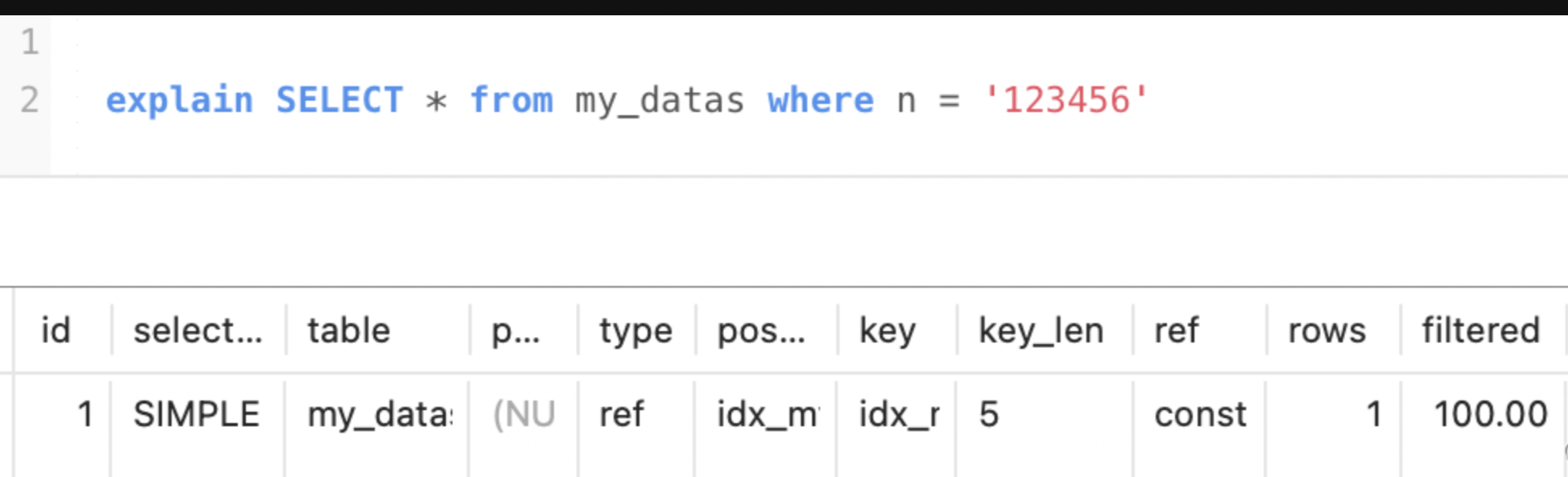
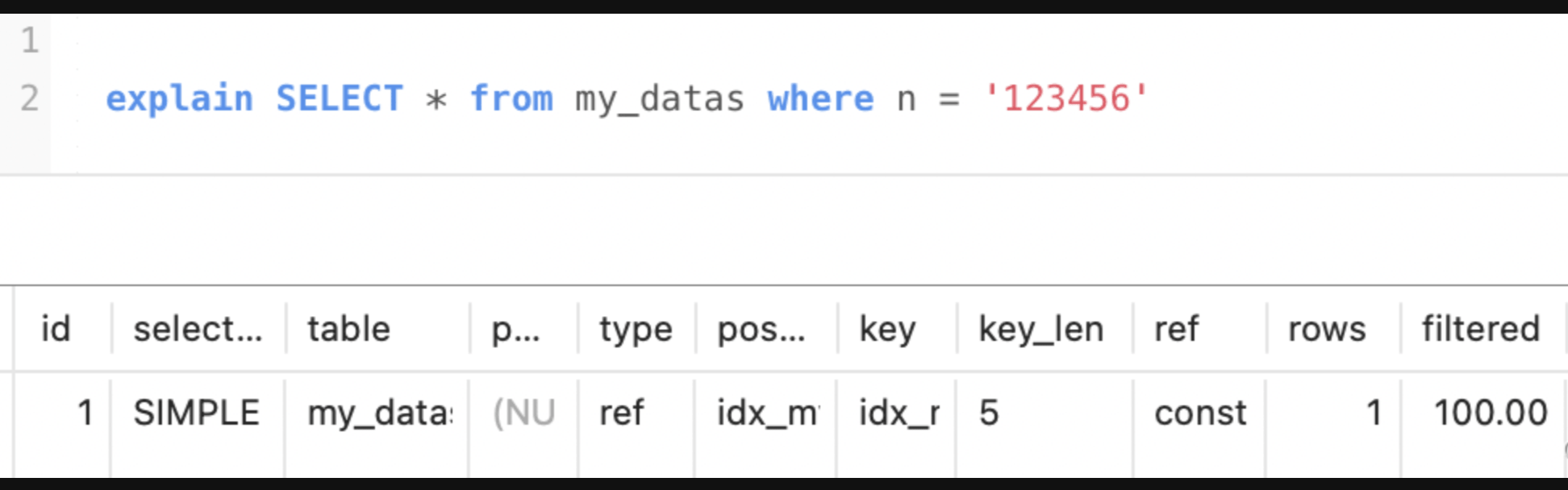
key_len=5,通过计算索引占的字节数来判断出查询使用了联合索引中的第一个列。
key_len的计算:(举几个类型)
测试表test1

字符串:char(n)和varchar(n),5.0.3以后版本中,n均代表字符数,而不是字节数,如果是utf-8,一个数字或字母占1个字节,一个汉字占3个字节
-
char(n):如果存汉字长度就是 4n 字节(若可为空 则+1)

col1_char是char(4),那么len应该是 4*4 + 可为空1 = 17 explain中key_len值为17
-
varchar(n):如果存汉字则长度是 4n + 2 字节(若可为空 则+1),加的2字节用来存储字符串长度,因为 varchar是变长字符串。
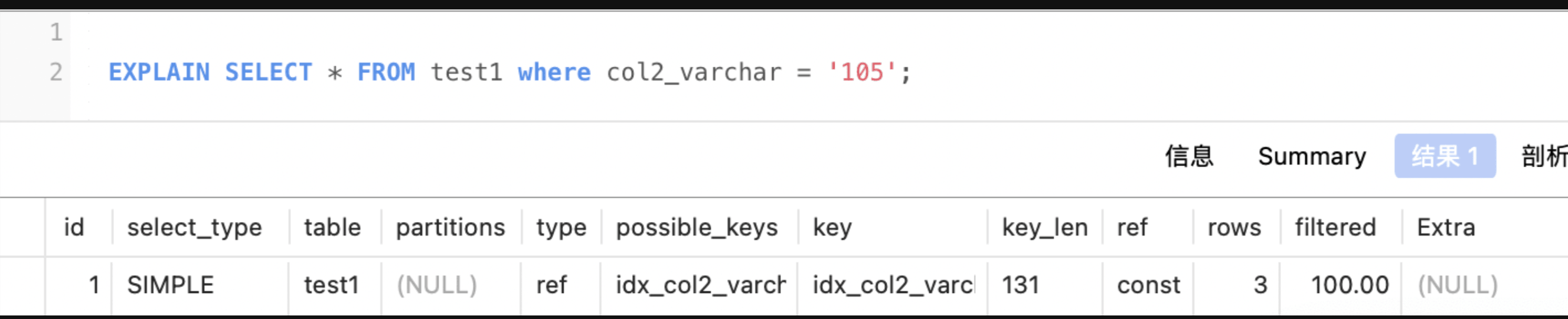
col2_varchar是varchar(32),那么len应该是 32 * 4 + 2 + 1 = 131 explain中key_len值为131
数值类型:
-
tinyint:1字节(若可为空 则+1)
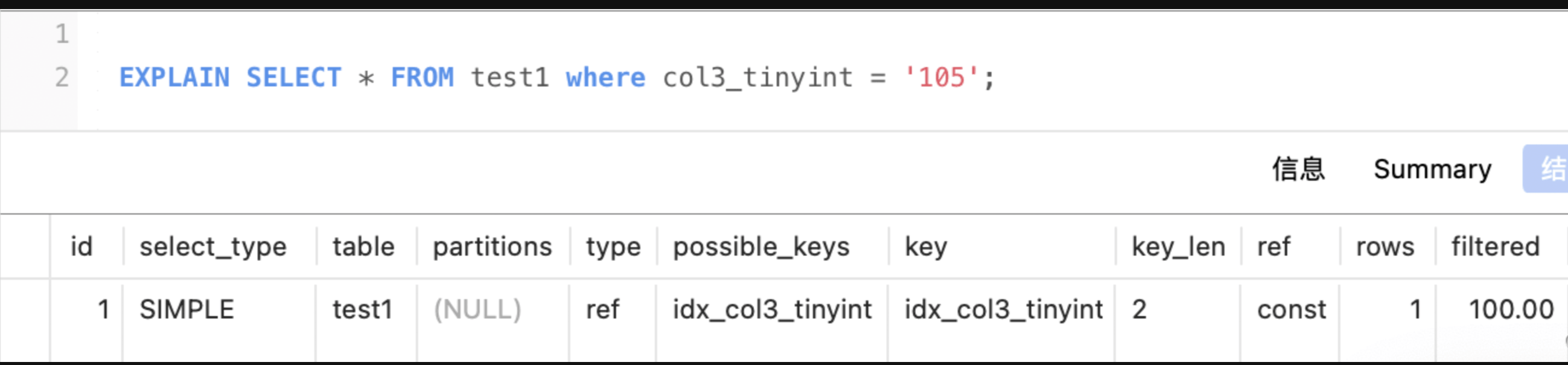
col3_tinyint是tinyint,那么len应该是 1+可为空1 = 2 explain中key_len值为2
-
smallint:2字节(若可为空 则+1)

col4_smallint是smallint,那么len应该是 2+可为空1 = 3 explain中key_len值为3
-
int:4字节(若可为空 则+1)
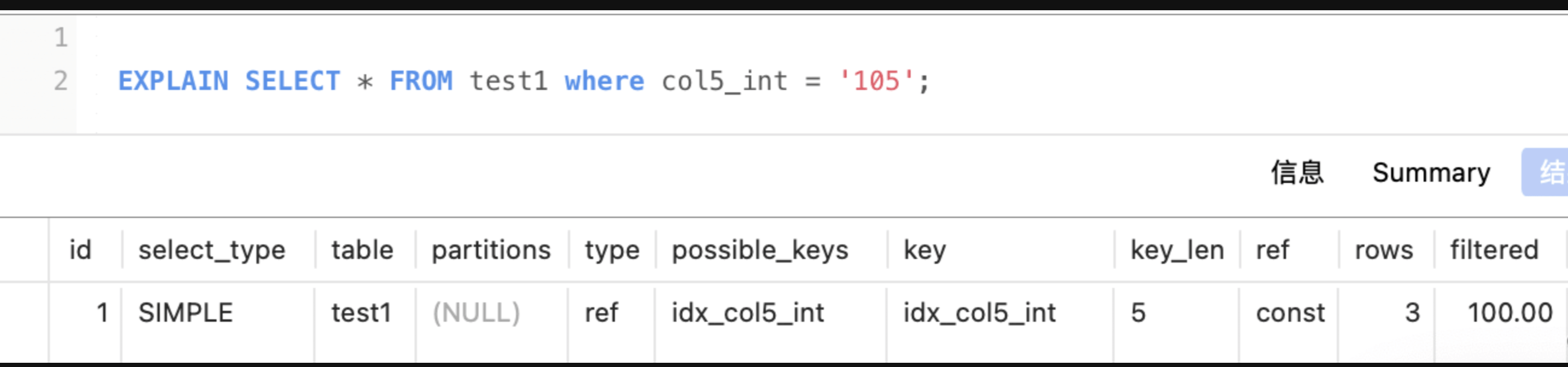
col5_int是int,那么len应该是 4+可为空1 = 5 explain中key_len值为5
-
bigint:8字节 (若可为空 则+1)
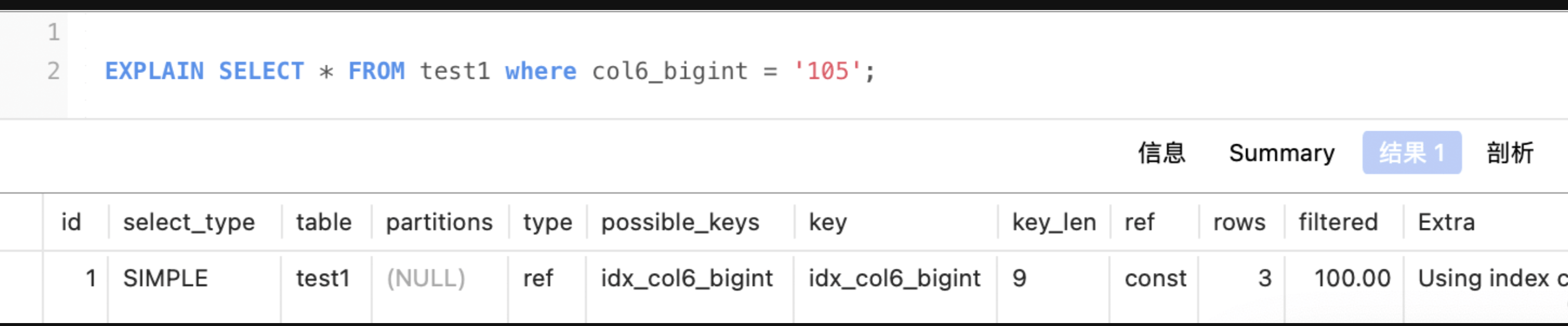
col6_bigint是bigint,那么len应该是 8+可为空1 = 9 explain中key_len值为9
时间类型:
-
date:3字节(若可为空 则+1)
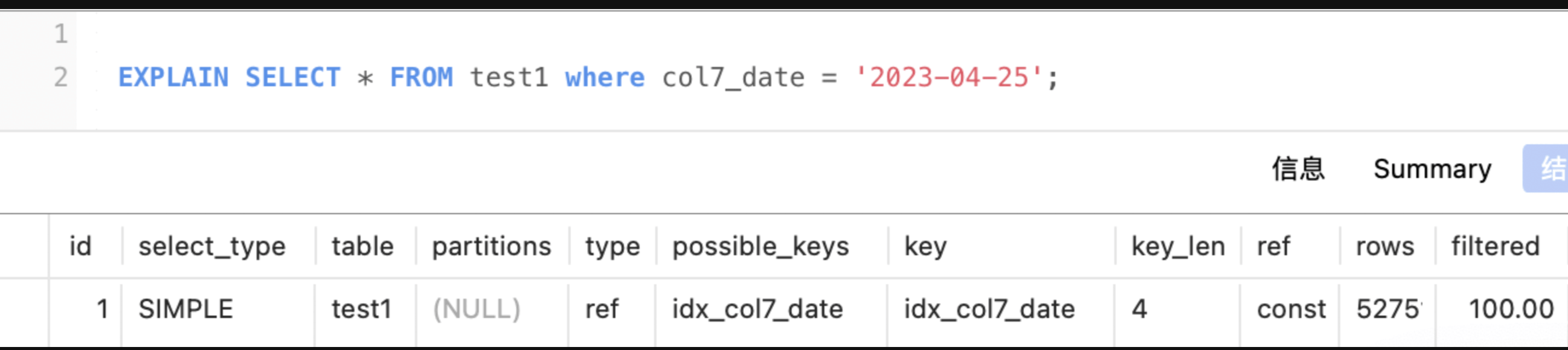
col7_date是date,那么len应该是 3 + 可为空1 = 4 explain中key_len值为4
-
timestamp:4字节(若可为空 则+1)
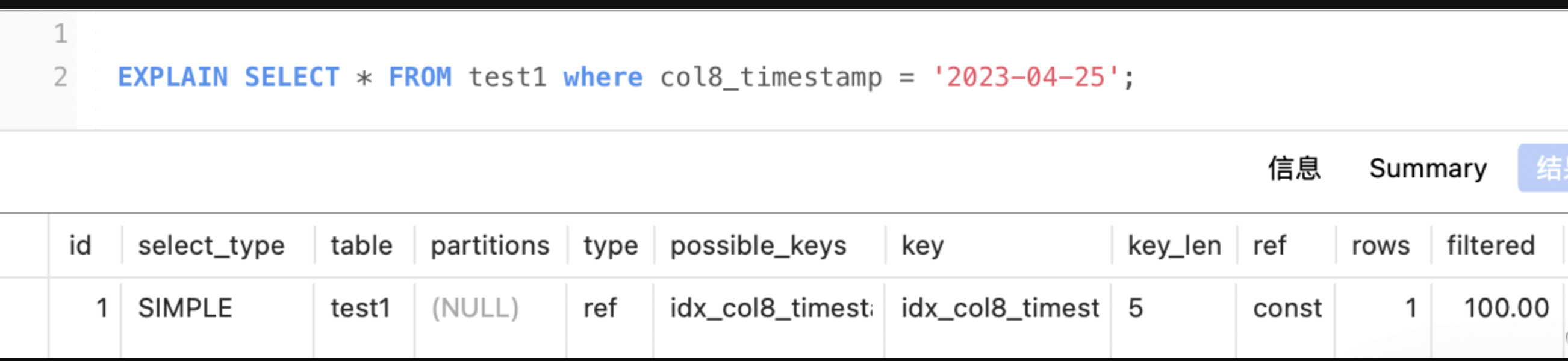
col8_timestamp是timestamp,那么len应该是 4+可为空1 = 5 explain中key_len值为5 datetime:无小数秒位数,占5个字节。datetime(n) 其中n是保留的小数秒位数,额外占的存储空间分别为 n=0时 额外空间0字节 n=1(或2) 额外空间1字节 n=3(或4) 额外空间2字节 n=5(或6) 额外空间3字节 col9_datetime是datetime,那么len应该是 5+可为空1 = 6 explain中key_len值为6
注:
- myisam 表,单列索引,最大长度不能超过 1000 bytes,否则会报警,但是创建成功,最终创建的是前缀索引(取前333个字符);
- myisam 表,组合索引,索引长度和不能超过 1000 bytes,否则会报错,创建失败;
- innodb 表,单列索引,超过 767 bytes的,给出warning,最终索引创建成功,取前缀索引(取前 255 字符);
- innodb 表,组合索引,各列长度不超过 767 bytes ,如果有超过 767 bytes 的,则给出报警,索引最后创建成功, 但是对于超过 767 字节的列取前缀索引,与索引列顺序无关,总和不得超过 3072 ,否则失败,无法创建;
ref
这一列显示了在key列记录的索引中,表查找值所用到的列或常量,常见的有:const(常量)、字段名(库名.表名.列名 如test.test.col1_char)
rows
这一列是mysql估计要读取并检测的行数,值越小越优
注意这个不是结果集里的行数
filtered
通过索引扫描表估计要读取并检测的行数rows。
使用额外的查询条件对rows行的数据进行过滤行得有行数n占rows的比例,
即 n/rows * 100%
Extra
sql执行计划比较重要的参考信息,常见重要信息如下:
-
1 Using index:使用索引覆盖
索引覆盖:查询的字段信息从这条sql使用的索引(辅助索引)树中获取。如: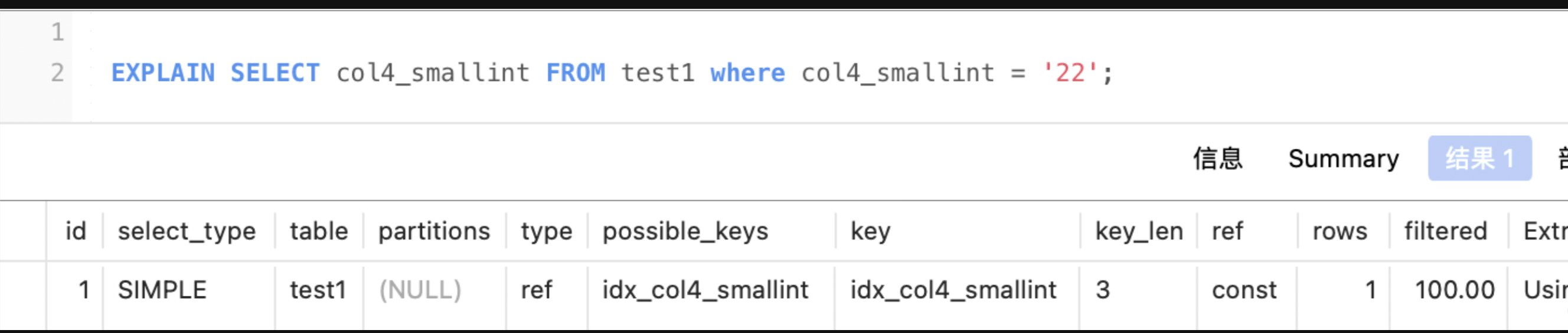
查询的字段是索引(col4_smallint)中的字段col4_smallint信息
也就是说,不需要通过辅助索引找到主键,再通过主键树获取想要的信息
- 2 Using where:使用where查询数据,需要回表去获取需要的数据

- 3 Using index condition:相当于索引覆盖后通过主键回表查询,再通过where过滤
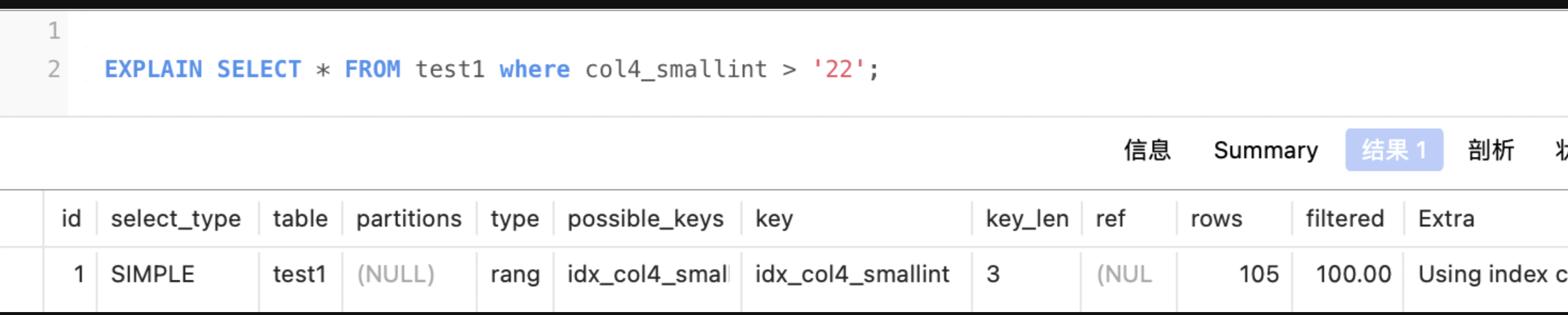
- 4 Using temporary:创建一张临时表来处理查询
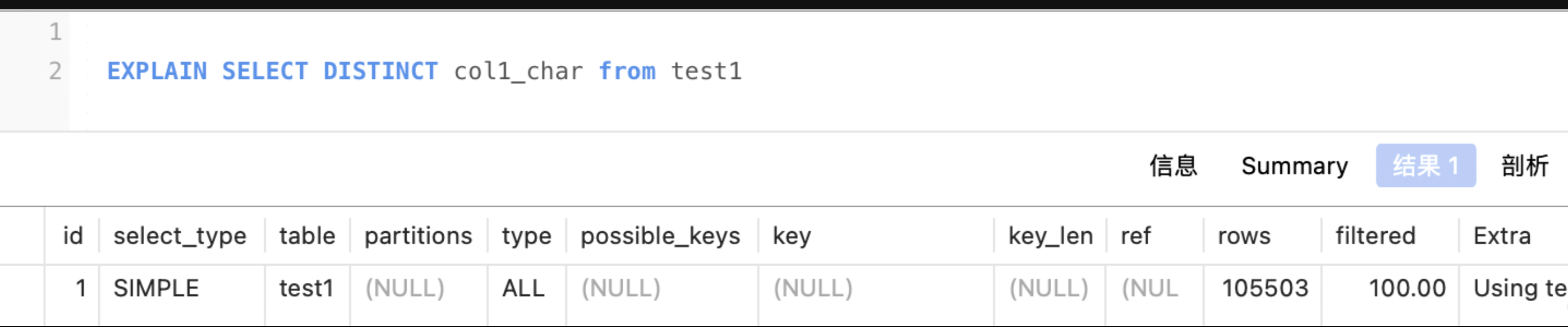
- 5 Using filesort:顾名思义,使用文件(磁盘中)排序。mysql做了优化,数据较少时排序是在内在中进行的,数据量较大时才会在磁盘中进行排序。出现这种情况,就要考虑添加索引来优化SQL了。
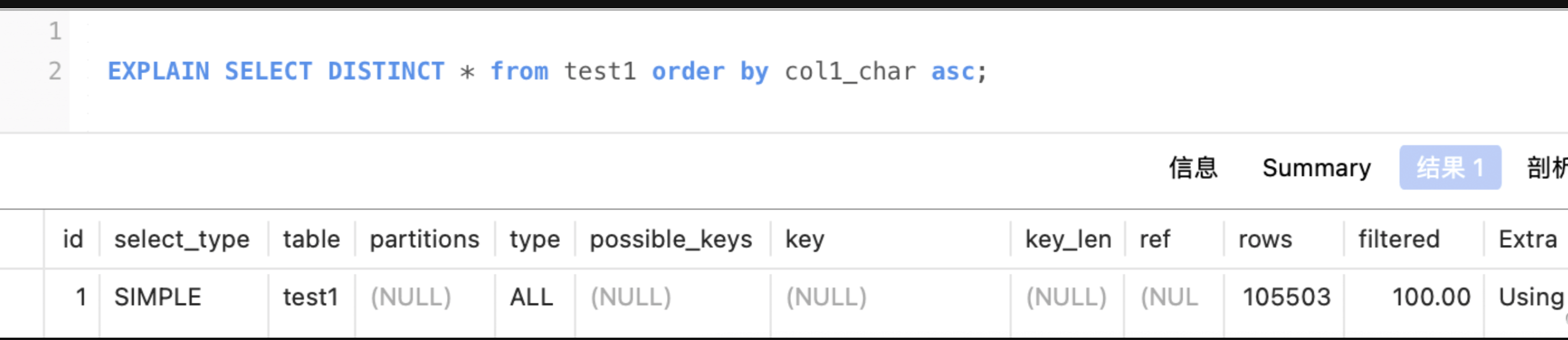
col1_char 未创建索引,mysql先预览整个表对col1_char进行排序和对应的主键值序列,再通过主键值回主键索引树查询数据返回。
对 col1_char 添加索引之后,执行计划结果如下:
6 Select tables optimized away:使用函数来查询某个索引信息时
-

总结
到此这篇关于轻松上手MYSQL之SQL优化之Explain详解的文章就介绍到这了,更多相关SQL优化Explain内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

