引言
随着我被拉入一个新的群聊“生产环境死锁问题排查解决”,打破了午后的悠然惬意,点开群聊秒送了一个648超级大礼包(业务不正常,死锁异常日志输出),领导怒斥并要求赶紧排除解决并总结经验,刚好我略懂略懂一点MySQL锁知识,这不得秀一下自己的实力
死锁的日志
既然死锁已经发生,也完全不要慌啊,按我说着做,一定能找到原因然后解决
触发下面这条命令获取到线索
SHOW ENGINE INNODB STATUS;
执行后你会得到一段让人看了有点迷迷的死锁日志,具体我们该怎么分析死锁,可以分成一下三步
- 查看发生死锁的事务(一)信息(包括持有的锁,等待的锁)
- 查看发生死锁的事务(二)信息(包括持有的锁,等待的锁)
- 查看回滚的是事务(一)还是事务(二),做好异常业务恢复的方案
- 根据mysql的加锁机制分析发生的死锁的原因
由于死锁日志过于长,下面的日志只截取部分有用的记录
------------------------
LATEST DETECTED DEADLOCK
------------------------
2022-10-14 15:51:34 0x1a00
发生死锁的事务(一)
*** (1) TRANSACTION:
TRANSACTION 32828384, ACTIVE 0 sec fetching rows
mysql tables in use 1, locked 1
LOCK WAIT 12 lock struct(s), heap size 1128, 285 row lock(s)
MySQL thread id 26352, OS thread handle 8548, query id 987590925 WIN-6Q9NIAJLCDR 172.27.15.57 swgj updating
事务(一)导致死锁的sql
update xxx
SET STATUS = '2',
DESCRIPTION = 'xxx',
MODIFY_TIME = '2022-10-14 15:51:35.707'
WHERE BATCH_NO = 'xxx'
and SFSB = '1'
事务(一)持有的锁
*** (1) HOLDS THE LOCK(S):
RECORD LOCKS space id 8575 page no 82 n bits 104 index PRIMARY of table `swgj`.`spgl_xmspsxblxxxxb` trx id 32828384 lock_mode X
事务(一)持有锁的数据记录信息 (supremum虚拟最大记录)
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
事务(一)持有锁的数据记录信息 (哪一行数据被锁了)
Record lock, heap no 2 PHYSICAL RECORD: n_fields 29; compact format; info bits 0
0: len 30; hex 30663730333038302d313164662d346439642d626338662d393439333333; asc 0f703080-11df-4d9d-bc8f-949333; (total 36 bytes);
1: len 6; hex 0000015129e1; asc Q) ;;
2: len 7; hex 010000402103cd; asc @! ;;
3: len 6; hex 313635303036; asc 165006;;
.....
.....
事务(一)等待的锁
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 8575 page no 37 n bits 112 index PRIMARY of table `swgj`.`spgl_xmspsxblxxxxb` trx id 32828384 lock_mode X waiting
事务(一)等待锁的数据记录信息
Record lock, heap no 45 PHYSICAL RECORD: n_fields 29; compact format; info bits 0
0: len 30; hex 32643736613832362d343763362d343861332d613038662d343539333061; asc 2d76a826-47c6-48a3-a08f-45930a; (total 36 bytes);
1: len 6; hex 000001f4ebdd; asc ;;
2: len 7; hex 820000402b3c96; asc @+
分析日志
从数据库版本5.7、事务的隔离级别 REPEATABLE READ
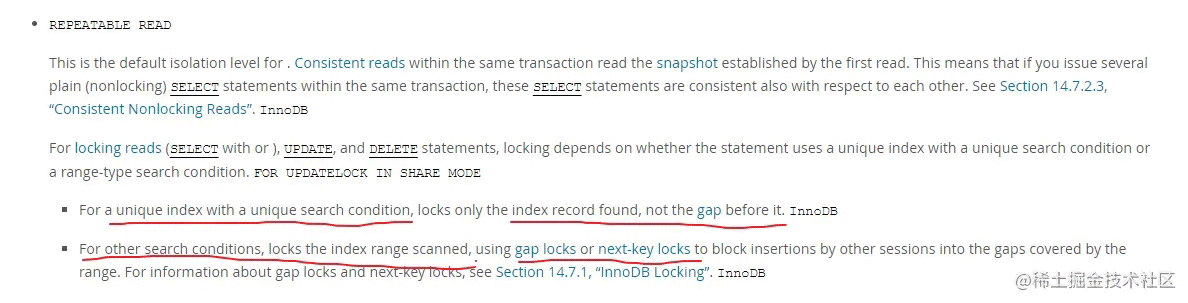
官方文档明确指出在 REPEATABLE READ 隔离级别下,默认查询条件下是加 next-key locks (record locks + gap locks ) 或 gap locks,当查询条件使用了唯一索引时,只会对当前查询的唯一记录进行加锁,此时锁为 record locks
官方文档强势占位
从死锁日志信息可以得出
- 根据事务id大小可得出事务(二)32828381 比事务(一)32828384 先执行
- 从日志中的 index PRIMARY 得出锁是加在主键索引上
- 根据业务代码,事务(二)将执行 N 条同表插入 insert 语句,加上持有锁信息得出,事务(二)先插入了一条新数据A,并得到新数据A的行锁 Record Locks
- 事务(一)执行 update 时直接阻塞,为什么呢,直接给出答案吧,因为这条 update 的查询条件是没有索引,导致需要所有的记录都要加 Record Locks 和 Gap Locks,接着由于事务(二)已经持有新数据A的行锁,导致无法上锁而阻塞等待
- 事务(二)继续插入一条新数据B时获取 insert intention locks 阻塞等待,很显然,事务(一)抢先占有插入数据上下索引的 Gap Locks,死锁产生,MySQL提示错误,并回滚事务(二)让事务(一)提交
复盘
接下来我将用一个小例子来复现这次死锁现象
- 建一个简单的表
CREATE TABLE `dead_lock` (
`id` varchar(10) NOT NULL,
`batch_no` varchar(10) DEFAULT NULL,
`status` varchar(1) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
INSERT INTO dead_lock (id,batch_no,status) VALUES
('10','1','1'),
('20','20','1'),
('30','30',NULL),
('32','32',NULL);
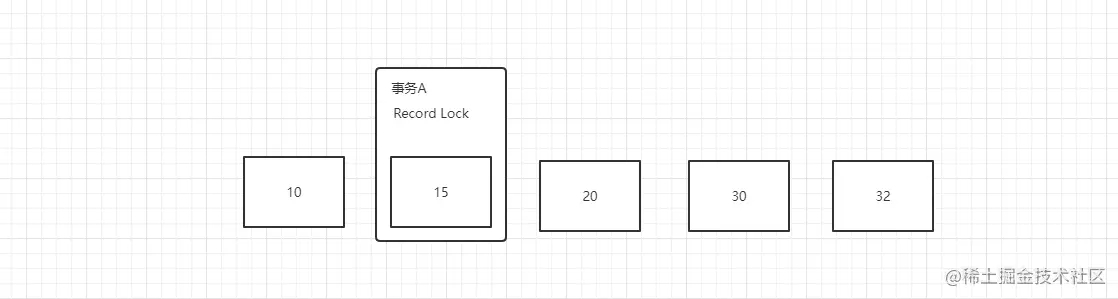
- 开始事务A进行插入数据,但先不提交
begin;
insert into dead_lock values ('34', '34', null);
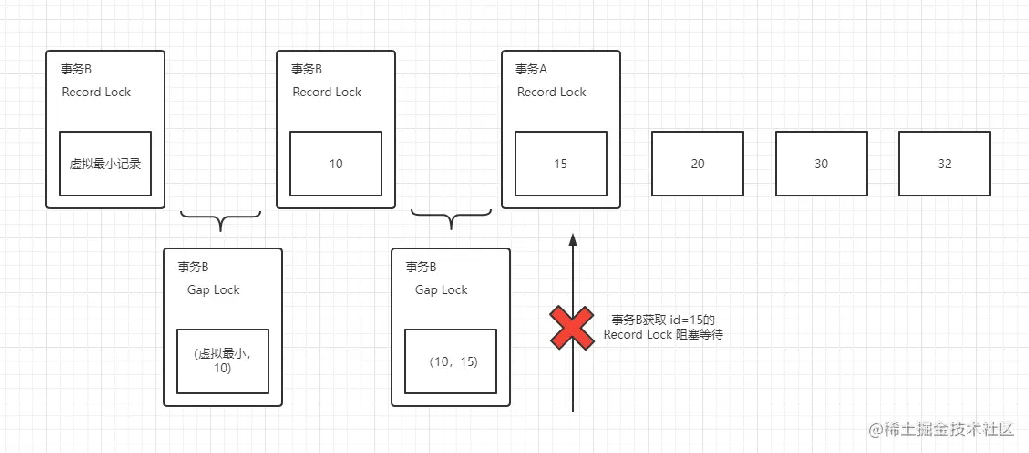
- 开始新的事务B进行更新数据,此时你会发现该事务被阻塞
begin; update dead_lock set status = '1' where batch_no = '20';
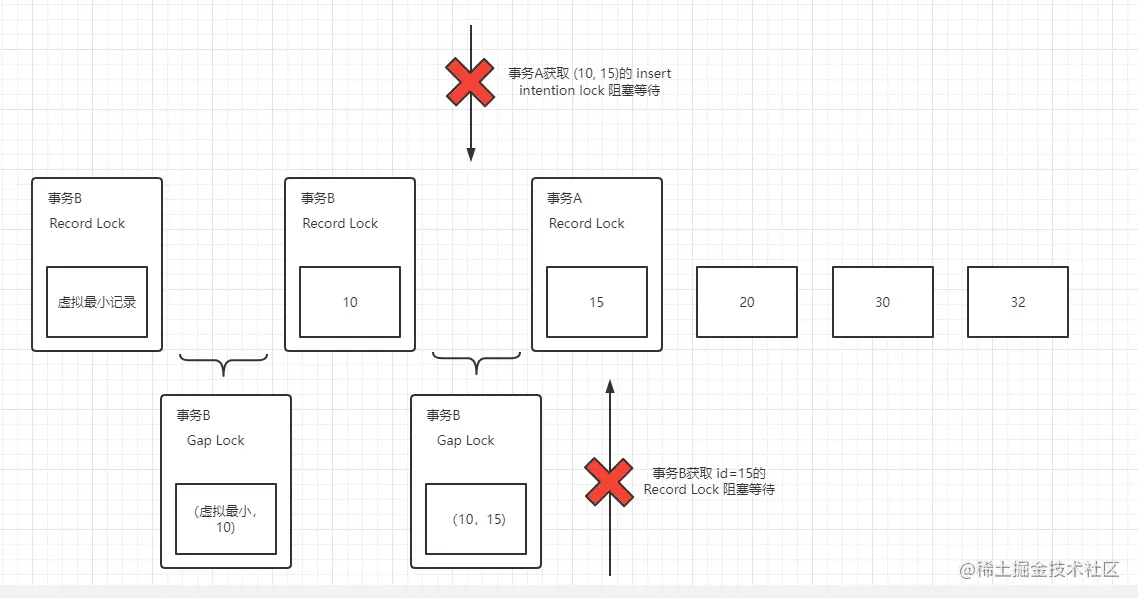
- 在事务A里插入一条特殊的数据,id为11的数据,当然不在事务B的持有锁的范围插入数据是不会造成死锁
insert into dead_lock values ('11', '11', null);
总结
在 MySQL 事务隔离级别 REPEATABLE READ 的情况下,对于 update,delete 等操作语句,查询条件尽量使用索引,减少锁的范围,提高写的并发量,避免不必要的死锁发生影响业务正常运行
这次死锁的说明就到这里,希望大家能看得懂并有所收获,不得不说有些知识我是略过了,大家可以自行查看官方文档补充了解,更多关于update where无索引MySQL死锁的资料请关注IT俱乐部其它相关文章!

