引言
1. 生成订单30分钟未支付,则自动取消
2. 30分钟未回复,则结束会话
对上述的任务,我们给一个专业的名字来形容,那就是延时任务
一、延时任务是什么
延时任务不同于一般的定时任务,延时任务是在某事件触发后的未来某个时刻执行,没有重复的执行周期。
二、延时任务和定时任务的区别是什么
- 定时任务有明确的触发时间,延时任务没有
- 定时任务有执行周期,而延时任务在某事件触发后一段时间内执行,没有执行周期
定时任务一般执行的是批处理多个任务,而延时任务一般是单任务处理
三、技术对比
本文主要讲解Redis的Zset实现延时任务,其他方案只做介绍
1.数据库轮询
通过定时组件的去扫描数据库,通过时间来判断是否有超时的订单,然后进行update或delete等操作
优点:
简单易行
缺点:
- 对服务器内存消耗大
- 时间间隔小,数据库损耗极大
- 数据内存态,不可靠
- 如果任务量过大,对数据库造成的压力很大 。频繁查询数据库带来性能影响
2.JDK的延迟队列
利用JDK自带的DelayQueue来实现,这是一个无界阻塞队列,该队列只有在延迟期满的时候才能从中获取元素,放入DelayQueue中,是必须实现Delayed接口的。
优点:实现简单,效率高,任务触发时间延迟低。
缺点:
- 服务器重启后,数据全部消失,怕宕机
- 因为内存条件限制的原因,比如下单未付款的订单数太多,那么很容易就出现OOM异常
- 数据内存态,不可靠
3.时间轮算法
时间轮TimingWheel是一种高效、低延迟的调度数据结构,底层采用数组实现存储任务列表的环形队列,示意图如下:时间轮
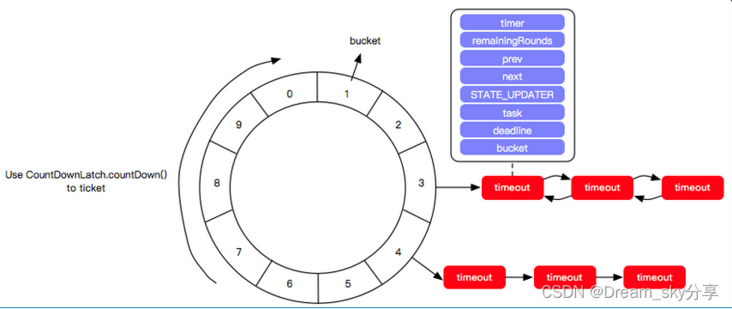
时间轮算法可以类比于时钟,如上图箭头(指针)按某一个方向按固定频率轮动,每一次跳动称为一个 tick。这样可以看出定时轮由个3个重要的属数,ticksPerWheel(一轮的tick数),tickDuration(一个tick的持续时间)以及 timeUnit(时间单位),例如当ticksPerWheel=60,tickDuration=1,timeUnit=秒,这就和现实中的始终的秒针走动完全类似了。
如果当前指针指在1上面,我有一个任务需要4秒以后执行,那么这个执行的线程回调或者消息将会被放在5上。那如果需要在20秒之后执行怎么办,由于这个环形结构槽数只到8,如果要20秒,指针需要多转2圈。位置是在2圈之后的5上面(20 % 8 + 1)
优点:效率高,任务触发时间延迟时间比delayQueue低
缺点:
- 服务器重启后,数据全部消失,怕宕机
- 容易就出现OOM异常
- 数据内存态,不可靠
4.使用消息队列
使用RabbitMQ死信队列依赖于RabbitMQ的两个特性:TTL和DLX。
TTL:Time To Live,消息存活时间,包括两个维度:队列消息存活时间和消息本身的存活时间。
DLX:Dead Letter Exchange,死信交换器。
优点:异步交互可以削峰,高效,可以利用rabbitmq的分布式特性轻易的进行横向扩展,消息支持持久化增加了可靠性。
缺点:
1.本身的易用度要依赖于rabbitMq的运维.因为要引用rabbitMq,所以复杂度和成本变高
2.RabbitMq是一个消息中间件;延迟队列只是其中一个小功能,如果团队技术栈中本来就是使用RabbitMq那还好,如果不是,那为了使用延迟队列而去部署一套RabbitMq成本有点大;
5.Redis的Zset实现延时任务
为什么采用Redis的ZSet实现延迟任务?
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序
5.1 思路分析
- 项目启动时启用
一条线程,线程用于间隔一定时间去查询redis的待执行任务。其任务jobId为业务id,值为要执行的时间。 - 查询到执行的任务时,将其从redis的信息中进行删除。(
删除成功才执行延时任务,否则不执行,这样可以避免分布式系统延时任务多次执行。) - 删除redis中的记录之后,执行任务。将执行jobId也就是业务id对应的任务。
实际场景中,还会涉及延时任务修改,删除等,这些场景可以指定标记,修改标识即可,当然也可以在业务逻辑中做补充条件的判断。
5.2 Redis中Zset的简单介绍及使用
Redis 有序集合是 string 类型元素的集合,且不允许重复的成员。每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
常用命令
- ZADD命令 : 将一个或多个成员元素及其分数值加入到有序集当中,或者更新已存在成员的分数
- ZCARD命令 : 获取有序集合的成员数
- ZRANGEBYSCORE: 通过分数返回有序集合指定区间内的成员
- ZREM : 移除有序集合中的一个或多个成员
java中操作简单介绍
1.add(K key, V value, double score)
添加元素到变量中同时指定元素的分值。
redisTemplate.opsForZSet().add("zSetValue","A",1);
2.rangeByScore(K key, double min, double max)
根据设置的score获取区间值。
zSetValue = redisTemplate.opsForZSet().rangeByScore("zSetValue",1,2);
3.rangeByScore(K key, double min, double max,long offset, long count)
根据设置的score获取区间值从给定下标和给定长度获取最终值。
zSetValue = redisTemplate.opsForZSet().rangeByScore("zSetValue",1,5,1,3);
4.rangeWithScores(K key, long start, long end)
获取RedisZSetCommands.Tuples的区间值。
Set> typedTupleSet = redisTemplate.opsForZSet().rangeWithScores("typedTupleSet",1,3);
Iterator> iterator = typedTupleSet.iterator();
while (iterator.hasNext()){
ZSetOperations.TypedTuple
以下代码可以直接使用-基于Spring Boot项目
5.3 延时队列工厂
代码中注释有详细介绍
/**
* 延时队列工厂
*
**/
@Slf4j
public abstract class AbstractDelayQueueMachineFactory {
@Autowired
private RedisUtil redisUtil;
@Autowired
private ThreadPoolTaskExecutor asyncTaskExecutor;
/**
* 插入任务id
*
* @param jobId 任务id(队列内唯一)
* @param time 延时时间(单位 :毫秒)
* @return 是否插入成功
*/
public boolean addJob(String jobId, Integer time) {
Calendar instance = Calendar.getInstance();
//增加延时时间,获取最终触发时间
instance.add(Calendar.MILLISECOND, time);
long delayMillisecond = instance.getTimeInMillis();
log.info("延时队列添加问题{}",jobId);
return redisUtil.zAdd(setDelayQueueName(), delayMillisecond, jobId);
}
/**
* 删除任务id
*
* @param jobId 任务id(队列内唯一)
*/
public boolean removeJob(String jobId) {
Long num = redisUtil.zRemove(setDelayQueueName(), jobId);
if (num > 0) return true;
return false;
}
/**
* 延时队列机器开始运作
*/
private void startDelayQueueMachine() {
log.info("延时队列{}开始启动", setDelayQueueName());
// 监听redis队列
while (true) {
try {
// 获取当前时间前的任务列表
Set> tuples = redisUtil.zRangeByScore(setDelayQueueName(), 0, System.currentTimeMillis() );
// 如果任务不为空
if (!CollectionUtils.isEmpty(tuples)) {
log.info("延时任务开始执行:{}", JSONUtil.toJsonStr(tuples));
Iterator> iterator = tuples.iterator();
while (iterator.hasNext()){
ZSetOperations.TypedTuple
addJob方法是添加任务id和延时时间(单位毫秒)
redisUtil.zRangeByScore ::根据设置的score获取区间值
@PostConstruct注解:是针对Bean的初始化完成之后做一些事情,比如注册一些监听器..(初始化实现方案有很多可自行选择)
为什么先删除后执行业务逻辑?
删除成功才执行延时任务,否则不执行,这样可以避免分布式系统延时任务多次执行
5.4 RedisUtil工具类
@Component
@Slf4j
public class RedisUtil {
@Autowired
private RedisTemplate redisTemplate;
/**
* 向Zset里添加成员
*
* @param key key值
* @param score 分数,通常用于排序
* @param value 值
* @return 增加状态
*/
public boolean zAdd(String key, long score, String value) {
Boolean result = redisTemplate.opsForZSet().add(key, value, score);
return result;
}
/**
* 获取 某key 下 某一分值区间的队列
*
* @param key 缓存key
* @param from 开始时间
* @param to 结束时间
* @return 数据
*/
public Set> zRangeByScore(String key, int from, long to) {
Set> set = redisTemplate.opsForZSet().rangeByScoreWithScores(key, from, to);
return set;
}
/**
* 移除 Zset队列值
*
* @param key key值
* @param value 删除的集合
* @return 删除数量
*/
public Long zRemove(String key, String... value) {
return redisTemplate.opsForZSet().remove(key, value);
}
}
5.5 测试延时队列
继承上文中的延时队列工厂重写invoke(处理业务)和setDelayQueueName–延时队列名称也就是Zset中的key值
/**
* 测试延时队列
*
*/
@Slf4j
@Component
public class DelayQueue extends AbstractDelayQueueMachineFactory {
@Autowired
private ZnjExpertConsultQuestionRecordMapper questionRecordMapper;
/**
* 处理业务逻辑
*/
@Override
public void invoke(String jobId) {
Integer questionId = Convert.toInt(jobId);
ZnjExpertConsultQuestionRecordEntity questionRecordEntity = questionRecordMapper.selectById(questionId);
Boolean flag = znjExpertConsultService.whetherEnd(questionRecordEntity);
/**
* 延时队列名统一设定
*/
@Override
public String setDelayQueueName() {
return "expert_consult:delay_queue";
}
}
运行成功,当Redis中有任务时,则执行任务即可

四、总结
使用redis zset来实现延时任务,总体类说是可行的
- 实时性: 允许存在一定时间内的误差(可以通过时间设定)
- 高可用性:支持单机,支持集群
- 消息可靠性: 保证至少被消费一次
- 消息持久化: 基于Redis自身的持久化特性,上面的消息可靠性基于Redis的持久化,所以如果redis数据丢失,意味着延迟消息的丢失,不过可以做主备和集群保证
以上就是Redis 延时任务实现及与定时任务区别详解的详细内容,更多关于Redis延时任务定时任务的资料请关注IT俱乐部其它相关文章!

