数据流转
在前端的javascrit中,我们几乎是没有能力对计算机上的某个文件进行读写操作的,毕竟js只是一个网页脚本。但是,nodejs是可以实现文件读写操作的。
在java中,对数据进行读写操作非常容易!下图展示了Java中数据流转的大致过程:
数据从数据源通过管道(stream)流转之数据目的地,管道的入口我们称之为input,出口称之为out,因此,数据流转操作也称之为IO操作。java中就封装了IO类帮助我们操作文件。

文件流操作
要操作一个文件,我们必须先创建文件对象,使用文件路径关联系统文件。
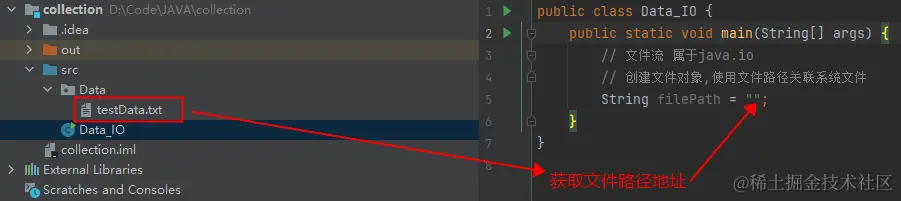
如图,我们Data文件夹有一个名 为testData的txt文件
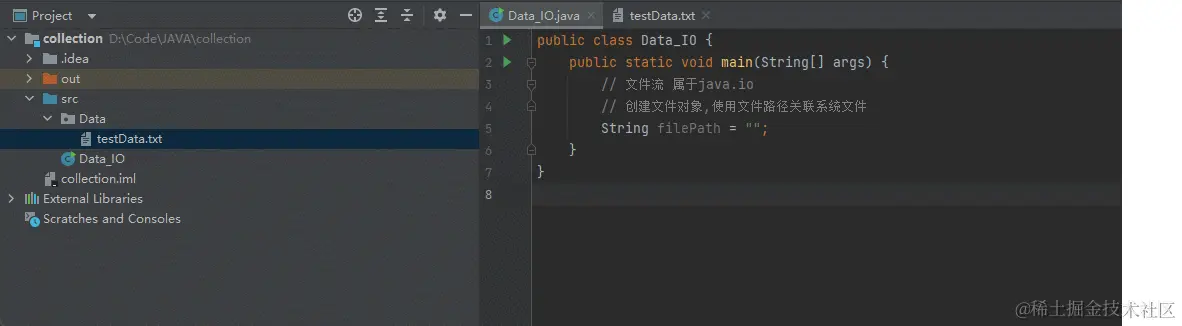
想要获得文件路径,我们可以按照下图的操作方式获取
关联好文件路径,我们就可以对文件进行一些操作了:
文件基础操作
import java.io.File;
public class Data_IO {
public static void main(String[] args) {
// 文件流操作 基于 java.io
// 使用文件路径关联系统文件
String filePath = "D:CodeJAVAcollectionsrcDatatestData.txt";
// 创建文件对象
File file = new File(filePath);
// 文件对象的操作
// 判断当前文件对象是否文件(File对象也可能是文件夹)
System.out.println(file.isFile()); // true
// 判断文件对象是否为文件夹
System.out.println(file.isDirectory()); // false
// 判断文件是否关联成功
System.out.println(file.exists()); // true
// 获取文件名称
System.out.println(file.getName()); // testData.txt
// 获取文件长度
System.out.println(file.lastModified()); // 1698977593862
// 获取文件的绝对路径
System.out.println(file.getAbsolutePath()); // D:CodeJAVAcollectionsrcDatatestData.txt
}
}
文件夹基础操作
文件夹的一些基础方法和文件是一致的。但有几个方法是文件夹操作独有的,如
获取文件夹内的数据列表
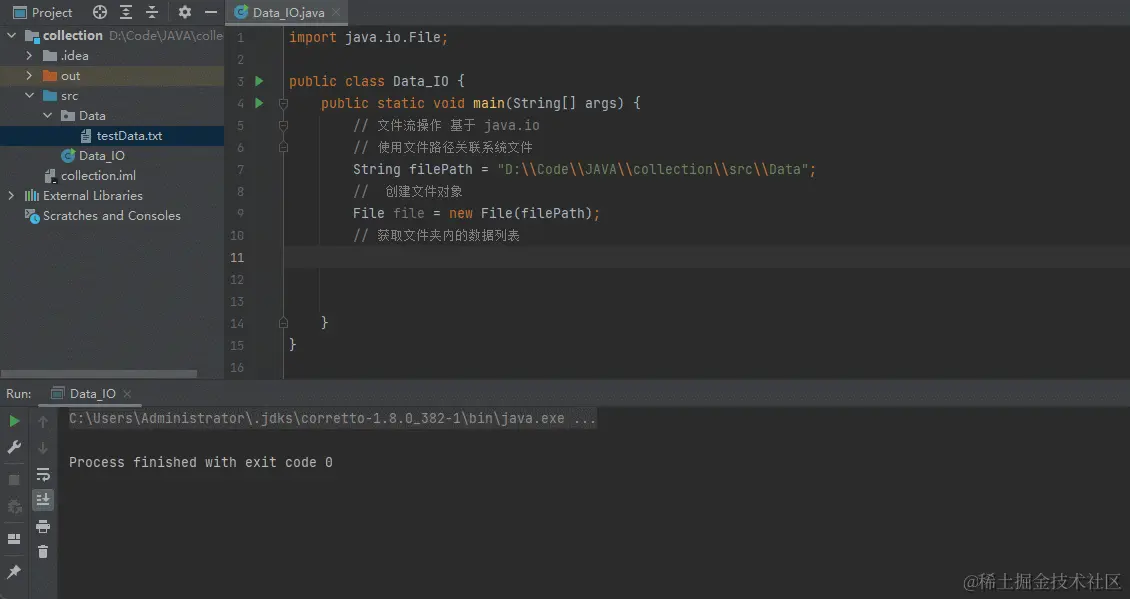
获取文件夹中的文件对象
File[] files = file.listFiles();
for (File file1 : files) {
System.out.println(file1 ); // testData.txt
}
文件复制
在java中,实现文件复制是一个稍微复杂的过程。现在,我们通过一个示例来演示下代码。我们需要在Data文件夹下创建一个testData的副本文件testData_copy.txt
java中,对象复制的流程大致如下模型

首先,我们需要数据源对象和数据目的对象:
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
}
}
数据目的对象的路径并不存在,是我们自己定义的要生成的文件路径。
然后,我们要创建文件输入管道1和文件输出管道2:
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
// 文件输入流(管道对象)
FileInputStream in = null;
// 文件输出流(管道对象)
FileOutputStream out = null;
}
}
接下来,我们就要打开阀门1和阀门2进行数据流转了
in = new FileInputStream(srcFile); out = new FileOutputStream(destFile); // 打开阀门,流转数据(输入端) int data = in.read(); // 打开阀门,流转数据(输出端) out.write(data);
数据流转完毕,我们需要关闭管道
in.close(); out.close();
当然,数据操作过程中,存在很多异常情况,比如找不到数据源文件等等,所以实际代码中,我们需要进行异常处理。比较完成的代码如下:
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
// 文件输入流(管道对象)
FileInputStream in = null;
// 文件输出流(管道对象)
FileOutputStream out = null;
try {
in = new FileInputStream(srcFile);
out = new FileOutputStream(destFile);
// 打开阀门1,流转数据(输入端)
int data = in.read();
// 打开阀门2,流转数据(输出端)
out.write(data);
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if(in != null){
try {
in.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(out != null){
try {
out.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
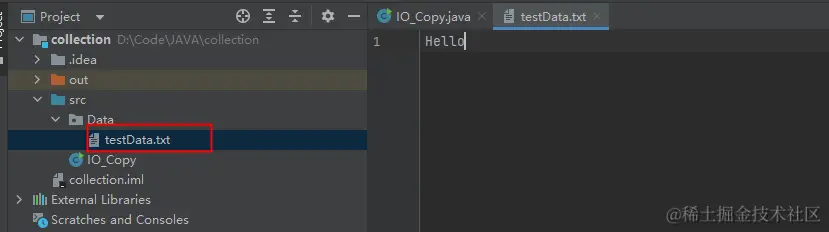
我们来运行看看
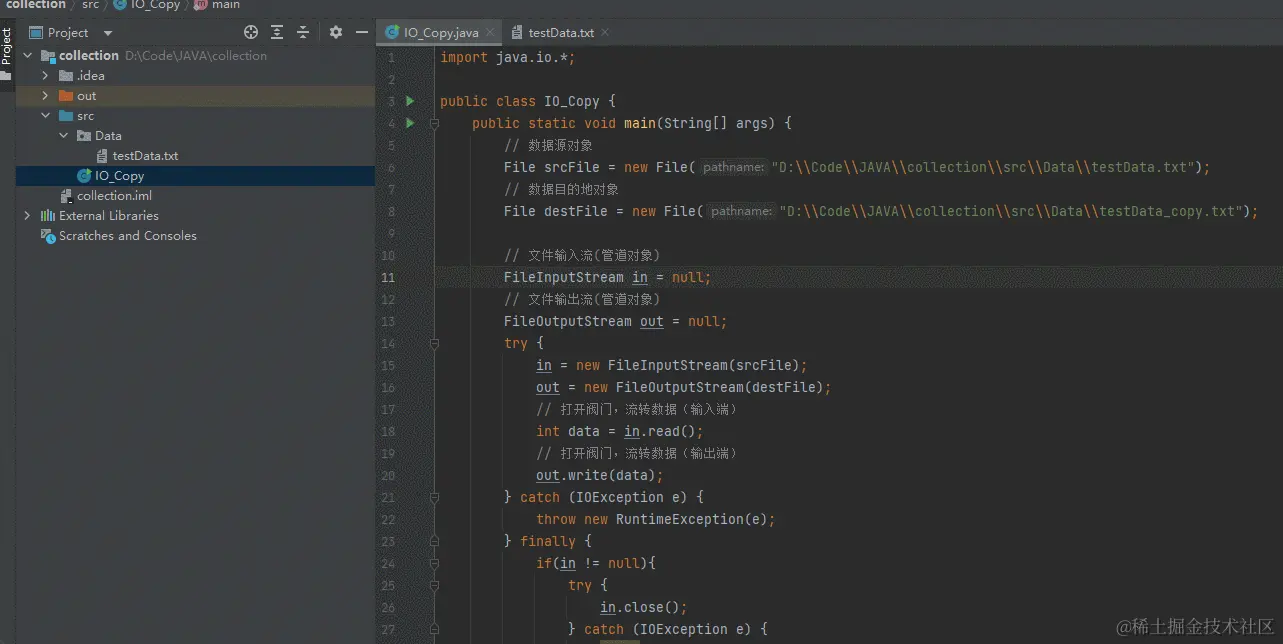
可以看到,文件复制的确完成了,但是为什么复制出来的文件只有一个H字符???
这其实和java的文件复制原理有关,文件流复制时,是这个过程:
复制时,阀门1打开,H字符进入管道1:

当H字符进入管道2时,阀门1关闭,阀门2打开

当H字符进入数据目的地后,阀门2也随之关闭,复制完成

在上述代码中,我们的阀门1和阀门2只开启过一次,自然只能复制一个H字符
in = new FileInputStream(srcFile); out = new FileOutputStream(destFile); // 打开阀门1,流转数据(输入端) int data = in.read(); // 打开阀门2,流转数据(输出端) out.write(data);
所以很简单,我们只需要循环执行上述代码即可!那该执行几次呢?我们看下面代码:
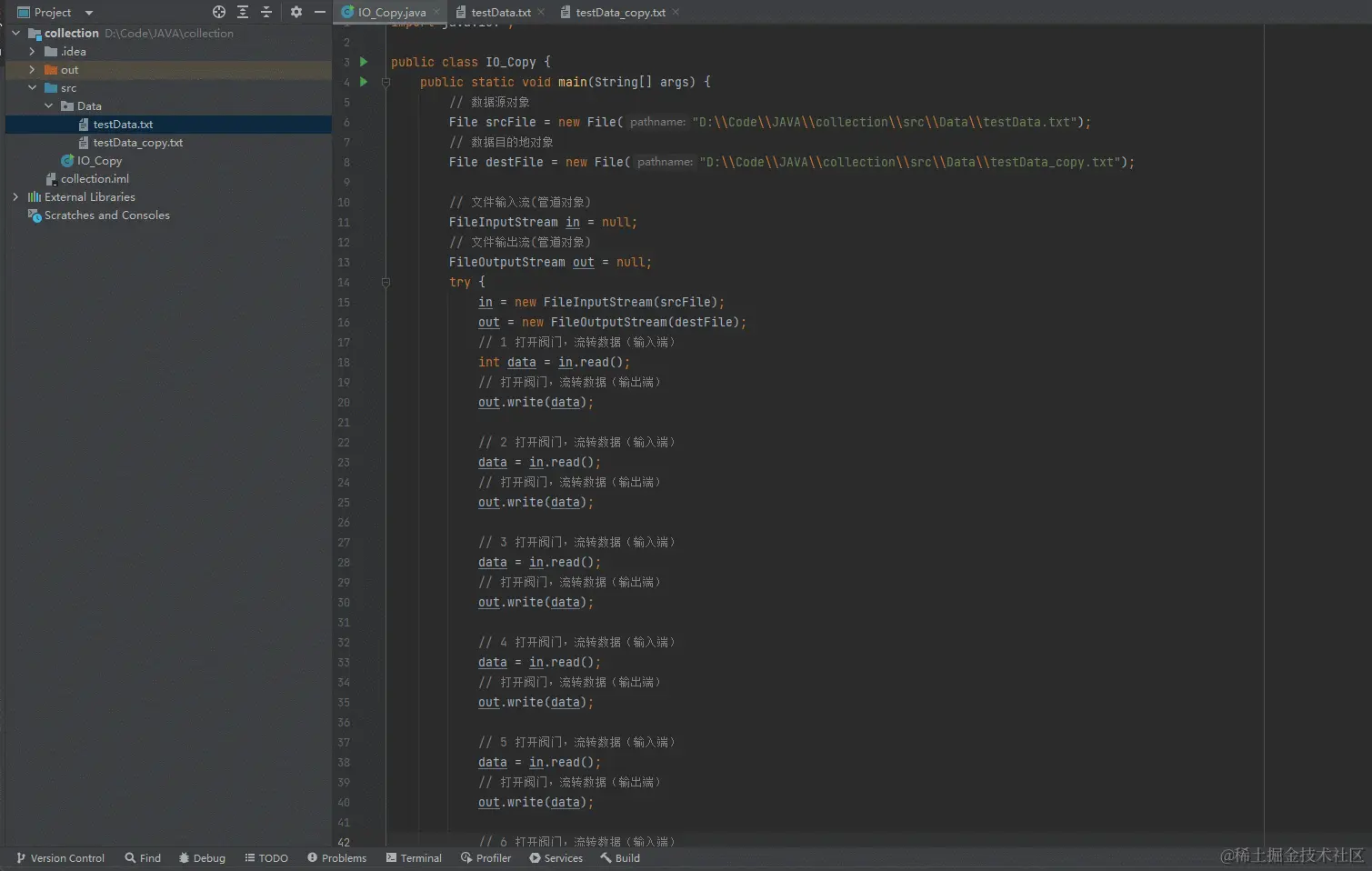
我们将阀门多开启了一次,导致副本文件多了一个乱码字符,通过打印结果可见,当data值为-1前,终止这个循环即可!改写代码:
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
// 文件输入流(管道对象)
FileInputStream in = null;
// 文件输出流(管道对象)
FileOutputStream out = null;
try {
in = new FileInputStream(srcFile);
out = new FileOutputStream(destFile);
// 打开阀门,流转数据(输入端)
int data = in.read();
out.write(data);
// 打开阀门,流转数据(输出端)
while ((data = in.read()) != -1){
out.write(data);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if(in != null){
try {
in.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(out != null){
try {
out.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
缓冲流
上述的文件复制效率很低,每复制一个字符,都要开启关闭阀门一次,因此,java也提供了缓冲区的优化方式。
它的概念非常容易,就是在文件传输的管道中,增加了一个缓冲管道
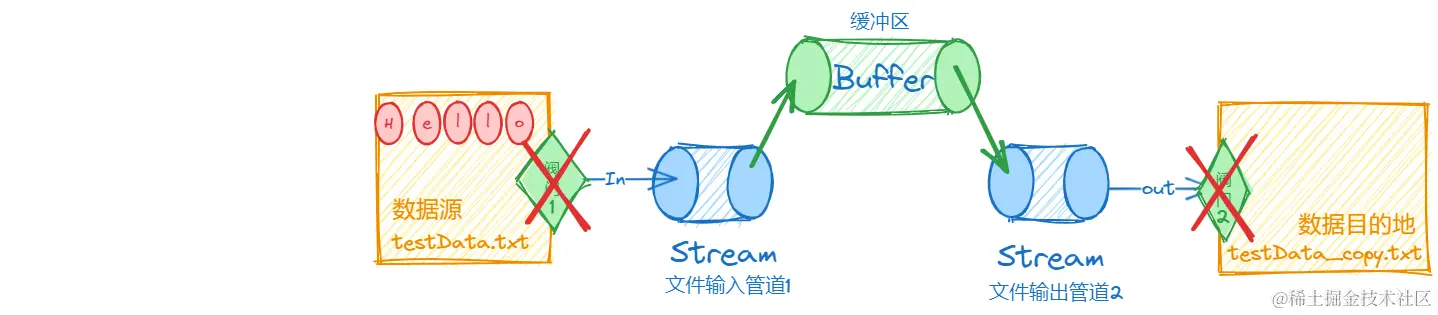
其复制流程大致如下:
阀门1打开,所有内容进入管道1
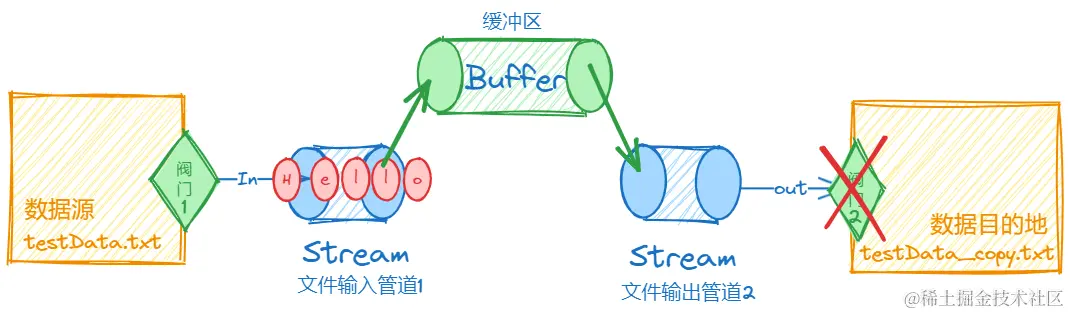
阀门1关闭,所有内容进入缓冲区
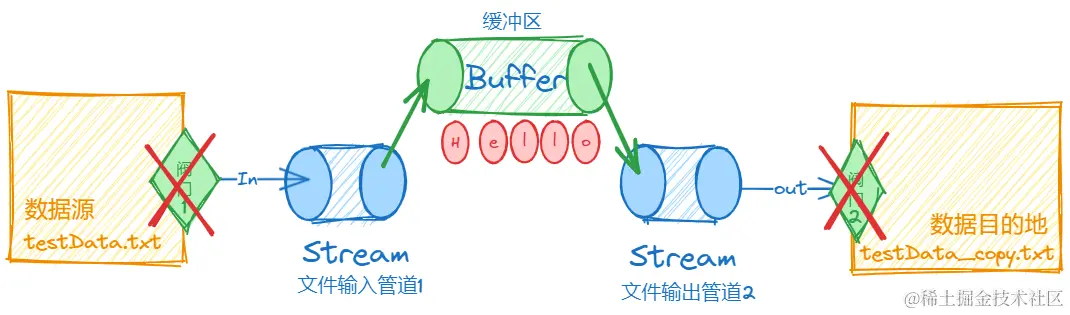
缓冲区内容进入管道2,阀门2打开
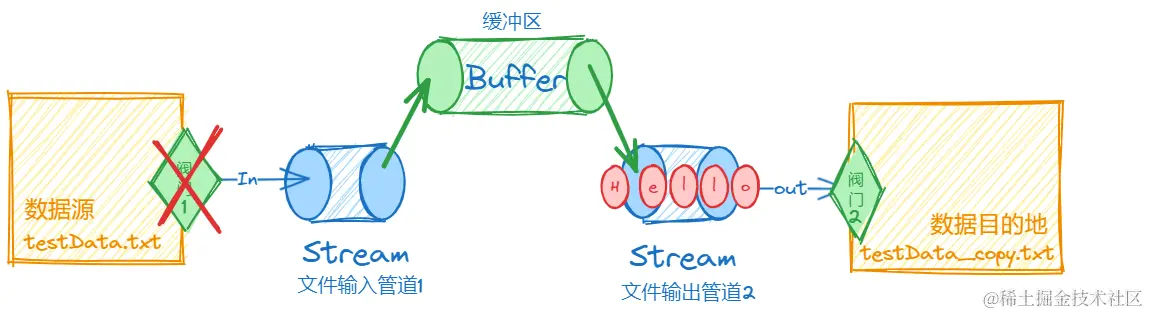
管道2内容进入数据目的地,复制完成,阀门2关闭。
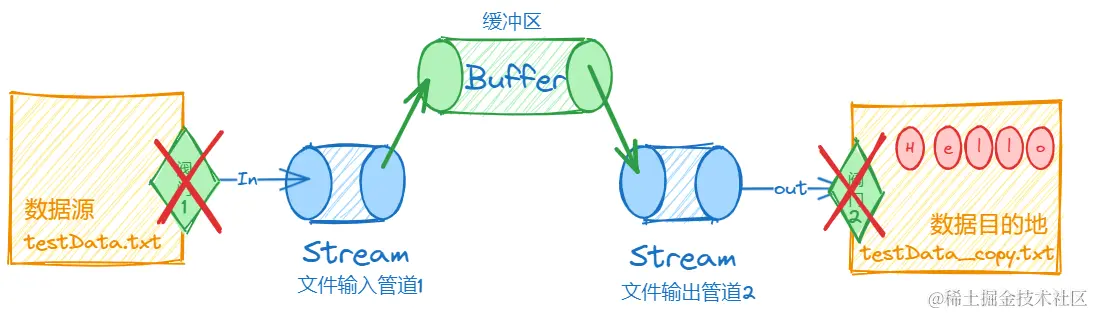
完整代码如下:
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
// 文件输入流(管道对象)
FileInputStream in = null;
// 文件输出流(管道对象)
FileOutputStream out = null;
// 缓冲输入流
BufferedInputStream bufferIn = null;
BufferedOutputStream bufferOut = null;
// 创建一个大小为1024字节的缓存区cache。这将用于存储从源文件读取的数据,然后再写入目标文件。
byte[] cache = new byte[1024];
try {
in = new FileInputStream(srcFile);
out = new FileOutputStream(destFile);
// 缓冲输入流
bufferIn = new BufferedInputStream(in);
// 缓冲输出流
bufferOut = new BufferedOutputStream(out);
// 数据流转
int data;
// 当读取到文件末尾(即data为-1)时,循环结束。
while ((data = bufferIn.read(cache)) != -1){
bufferOut.write(cache,0,data);
}
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if(bufferIn != null){
try {
bufferIn.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
if(bufferOut != null){
try {
bufferOut.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
字符流操作
文件流的操作是基于文件的字节实现的。字符流的操作提供了另一种通过一行字符的形式操作数据。

再文件复制时,它会将一整行的字符一次性复制过去。
它的语法流程如下
首先,定义两个File对象,srcFile和destFile。这两个对象分别代表了源文件(我们要从中读取数据的文件)和目标文件(我们要写入数据的文件)。
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
然后,创建了两个流对象,reader和writer。这两个对象分别用于从源文件读取数据和向目标文件写入数据。
BufferedReader reader = null; PrintWriter writer = null;
接着,使用reader读取源文件的内容,而writer会向目标文件写入内容。
try {
reader = new BufferedReader(new FileReader(srcFile));
writer = new PrintWriter(destFile);
...
} catch (IOException e) {
throw new RuntimeException(e);
}
在try块中,读取源文件的内容。每次读取一行,直到文件结束(也就是没有更多的行可以读取)。每读取一行,我们都会打印这一行(在控制台输出),并且写入到目标文件。
while ((line = reader.readLine()) != null){
System.out.println(line); // 打印到控制台
writer.println(line); // 写入到目标文件
}
在读取和写入操作结束后,我们调用writer.flush()方法,确保所有待写入的数据都被立即写入到目标文件。
writer.flush();
完整代码如下:
import java.io.*;
public class IO_Copy {
public static void main(String[] args) {
// 数据源对象
File srcFile = new File("D:CodeJAVAcollectionsrcDatatestData.txt");
// 数据目的地对象
File destFile = new File("D:CodeJAVAcollectionsrcDatatestData_copy.txt");
// 字符输入流(管道对象)
BufferedReader reader = null;
// 字符输出流(管道对象)
PrintWriter writer = null;
try {
reader = new BufferedReader(new FileReader(srcFile));
writer = new PrintWriter(destFile);
// 读取文件的一行数据(字符串)
String line = null;
while ((line = reader.readLine()) != null){
System.out.println(line); // Hello
writer.println(line);
}
// 刷写数据
writer.flush();
} catch (IOException e) {
throw new RuntimeException(e);
} finally {
if(reader != null){
try {
reader.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
}
以上就是一文带你搞懂Java中的数据流处理的详细内容,更多关于Java数据流处理的资料请关注IT俱乐部其它相关文章!

