Python pandas获取数据的行数和列数
import pandas as pd
df = pd.DataFrame({'Country':['China','China', 'India', 'India', 'America', 'Japan', 'China', 'India'],
'Income':[10000, 10000, 5000, 5002, 40000, 50000, 8000, 5000],
'Number':[5000, 4321, 1234, 4010, 250, 250, 4500, 4321]})

法一:
df.shape#返回df的行数和列数
输出:
(8, 3)
df.shape[0]#返回df的行数
输出:
8
df.shape[1]
输出:
3
法二:
df.info()
输出:

pandas获取数据以及数据概览
1 数据获取
先引入必要的库
import pandas as pd import numpy as np
1.1 读取数据
使用方法:pandas.read_csv()
参数:
(1)文件所在的路径
(2)headers:设置参数headers=None,pandas将不会自动将数据集的第一行设置为列表表头(列名)
other_path = "https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/auto.csv" df = pd.read_csv(other_path, header=None)
- 查阅数据集的前n行,使用函数df.head(n);
- 查阅数据集的倒数后n行,使用函数df.tail(n)
df.head(5)
输出:

df.tail(10)
输出:
1.2 为数据集添加列名(表头)
观察上面读取出来的部分数据,pandas自动将列名(表头)设置为从0开始的数字标签。

需要我们手动添加能够帮助我们更好理解数据的列名:
首先创建出一个列表headers,里面内容就是每列的名称,然后使用方法:df.columns = headers来将列名替换成我们刚才设置的。
headers = ["symboling","normalized-losses","make","fuel-type","aspiration", "num-of-doors","body-style",
"drive-wheels","engine-location","wheel-base", "length","width","height","curb-weight","engine-type",
"num-of-cylinders", "engine-size","fuel-system","bore","stroke","compression-ratio","horsepower",
"peak-rpm","city-mpg","highway-mpg","price"]
df.columns = headers
df.head(10)
输出:
1.3 删除某些具有空值的“脏数据”
观察上面的部分数据,发现有一些值为“?” 的行代表空值,首先需要先将这些“?”标志替换为NaN,然后使用方法dropna()来移除这些脏数据。
df1=df.replace('?',np.NaN)
下面使用方法dropna来删除脏数据行。
关于方法dropna():
参数:
(1)axis: default 0指删除行,1为删除列
(2)subset:对特定的列进行缺失值删除处理
(3)how: {‘any’, ‘all’}, default ‘any’指带缺失值的所有行;’all’指清除全是缺失值的
(4)thresh:int,保留含有int个非空值的行
(5)inplace:True表示直接在原数据上更改
df=df1.dropna(subset=["price"], axis=0) df.head(20)
上面的调用,表示,删除“price”列为空值的行。
输出:
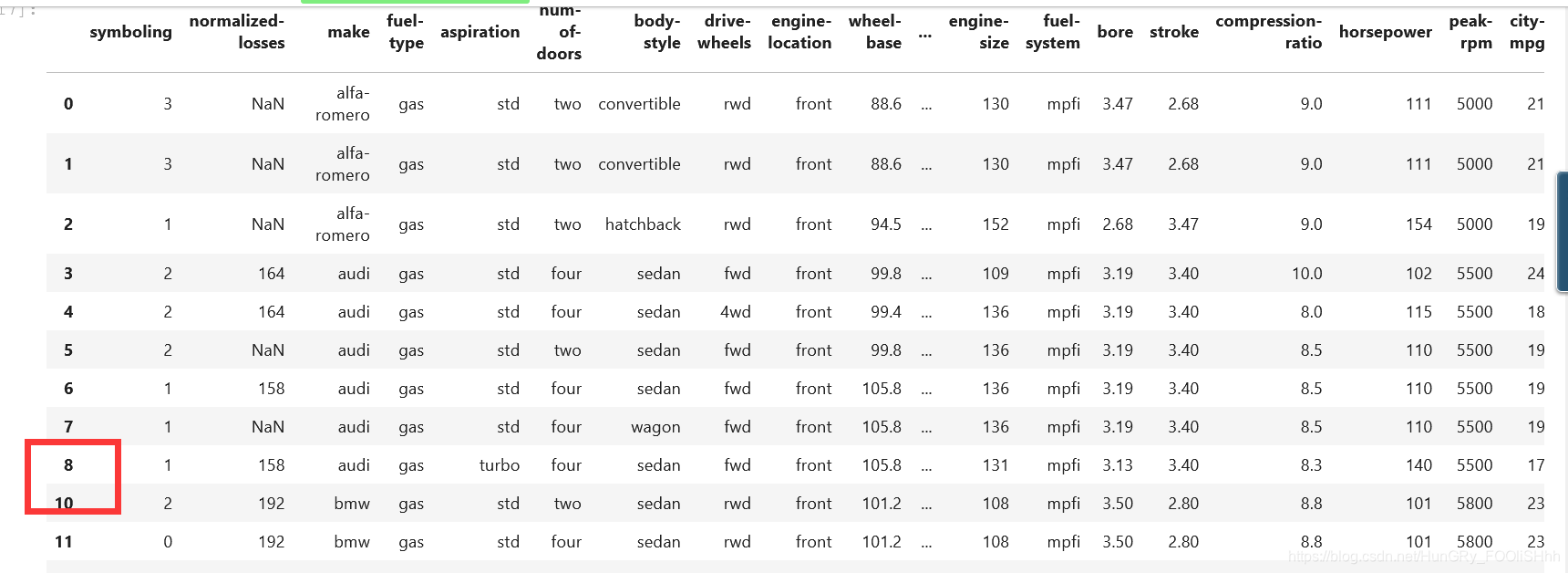
可以看出,原来行9的“price”列为空值,所以行9被删除。
1.4 查看数据的列名列表
df.columns
输出:

1.5 保存某个数据集
我们可以将处理过的dataframe(df)保存成某种格式(例如:.csv)的文件,方便以后进行读取。
使用方法df.to_csv(“文件要保存的路径”, index = False)
df.to_csv("automobile.csv", index=False)
注:参数index的含义为“是否保留行索引”, 默认为True
当然我们可以读取其他格式的数据,对数据操作完成后,我们也同样可以将数据保存为不同的格式,下图显示了读取其他格式文件以及将数据集保存为其他格式的方法:

2 数据概览
2.1 查看每列数据的类型
dataframe的属性dtypes可以返回表示每列数据名称及类型的列表:
print(df.dtypes)
输出:
第一列为列名,第二列为数据的类型

2.2 获取每列数据的统计特征(eg:总行数,列数据的平均值、标准差,etc)
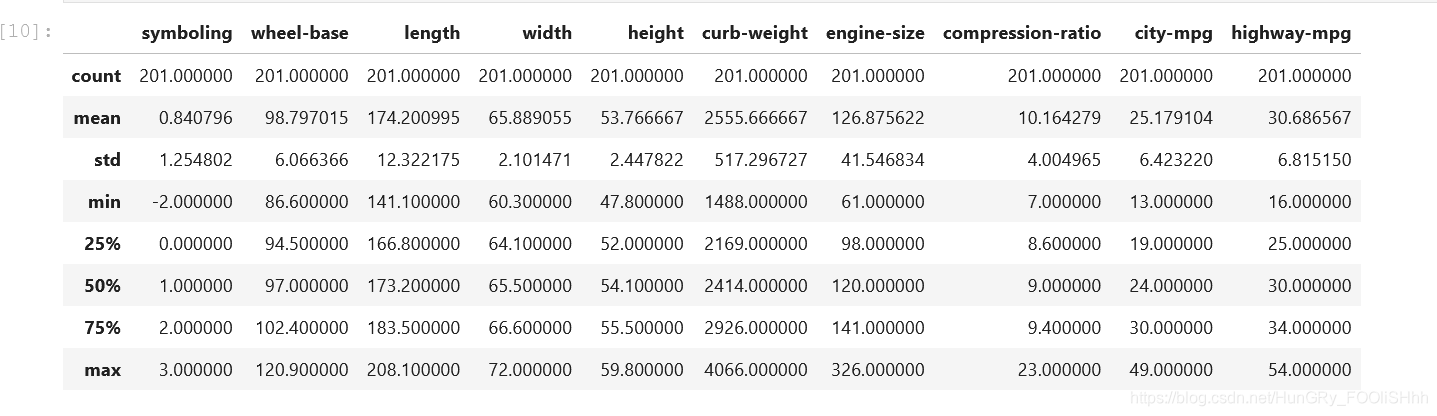
使用:dataframe.describe()即可查看每列数据的
(1)总行数统计count
(2)平均值mean
(3)标准差std
(4)最小值min
(5)25%分位值“25%”
(6)50%分位值“50%”
(7)75%分位值“75%”
(8)最大值max
df.describe()
输出:
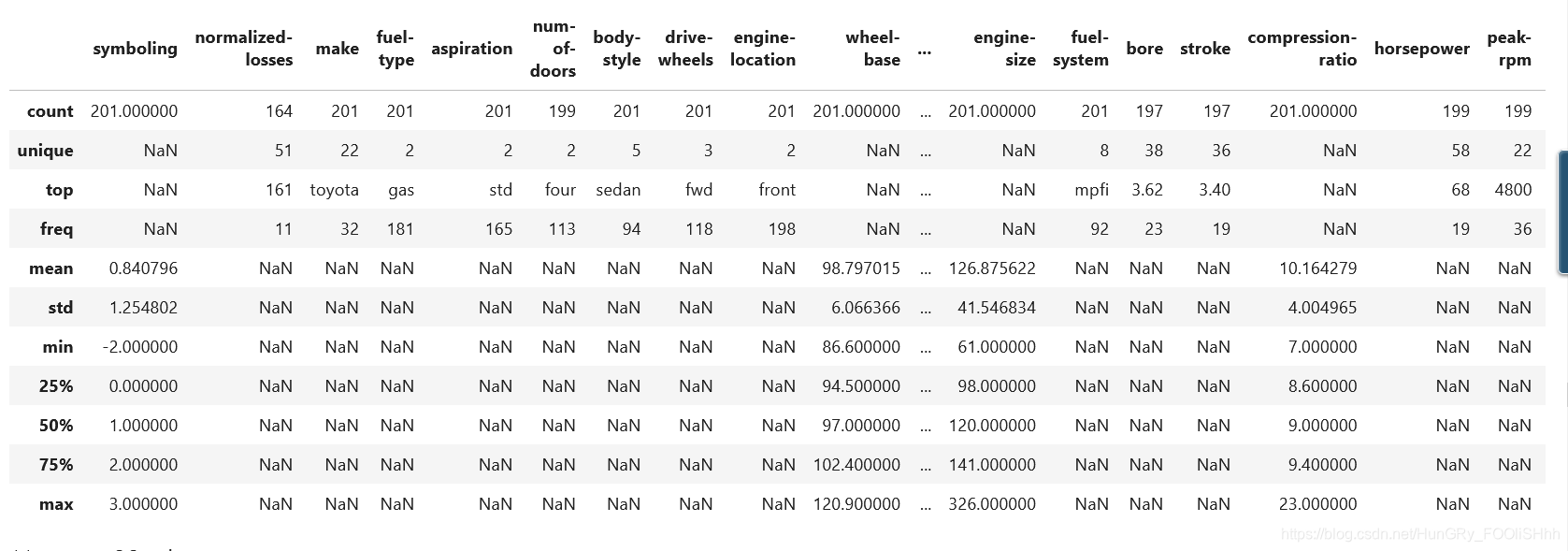
注意:方法describe()只统计(没有任何参数的情况下)数据类型(numeric-typed数据类型,例如int,float等)列的统计特征,并且会自动NaN值。
如果我们想查看所有列的统计特征(即包括非数据类型的列,例如object类型的列),就需要在describe()方法中添加参数(include = “all”)
df.describe(include = "all")
输出:
2.3 获取指定列的统计学特征
使用如下语句:
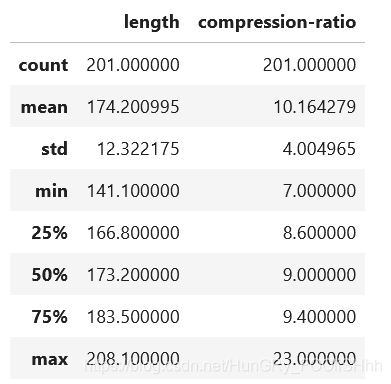
dataframe[[‘column1’, ‘column2’, ‘column3’]].describe()
df[['length', 'compression-ratio']].describe()
输出:
2.4 使用方法info()来查看dataframe的简介描述
使用如下语句:
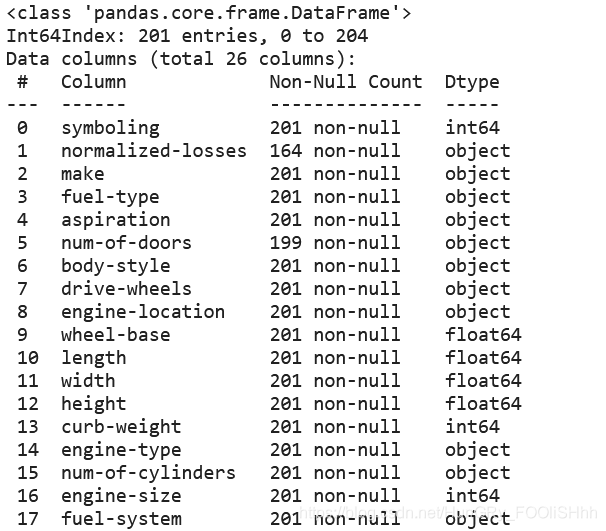
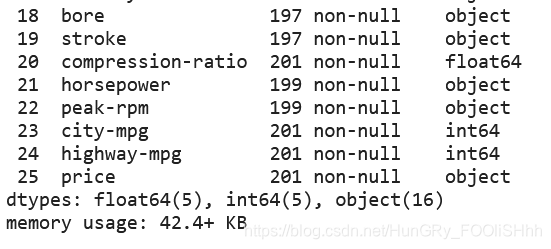
dataframe.info()
此方法打印有关dataframe的信息,包括索引dtype和列、非空值和内存使用情况。
df.info()
输出:
2.5 查看数据的行数及列数
通过属性shape,获取数据集的(行数,列数)
ratings_df.shape
输出:
(463, 19)
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持IT俱乐部。

