
背景
数据分列在数据处理中很常见,数据分列一般指的都是字符串分割,这个功能在Excel里面很实用,处理数据非常方便,那么在pandas数据框中怎么使用呢,今天这篇文章就来详细介绍下
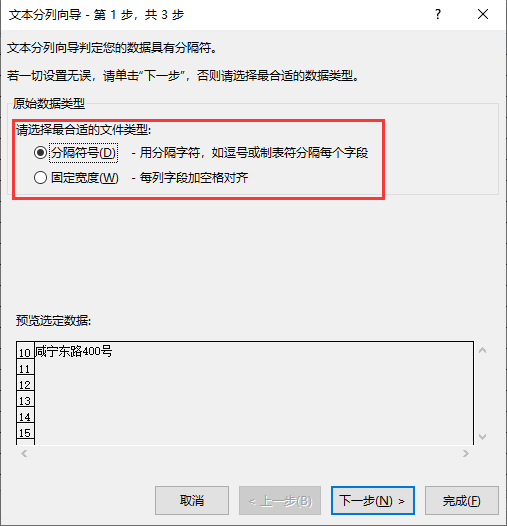
分列
模拟数据
以下面这9行数据作为案例来进行处理
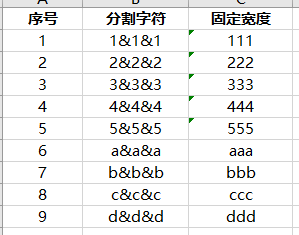
模拟数据
读取数据
1 2 3 4 5 | #加载库import pandas as pd#读取数据data=pd.read_excel('data.xlsx') |
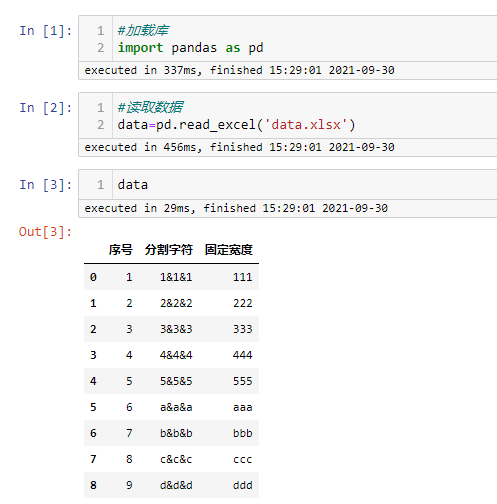
读取数据
分割符号分列
主要运用了pandas里面列的str属性,str有很多的方法,感性的同学可以自动查找,这里不做过多介绍。分割字符用到的就是split方法重点:在分割前一定要把该列强制转换为字符型
1 2 3 4 5 6 7 8 | #对指定列进行分割split_data_1=data['分割字符'].astype('str').str.split('&',expand=True)#修改分割后的字段名称split_data_1.columns=['D_'+str(i) for i in split_data_1.columns]#与原始数据进行合并data_result=data.join(split_data_1) |
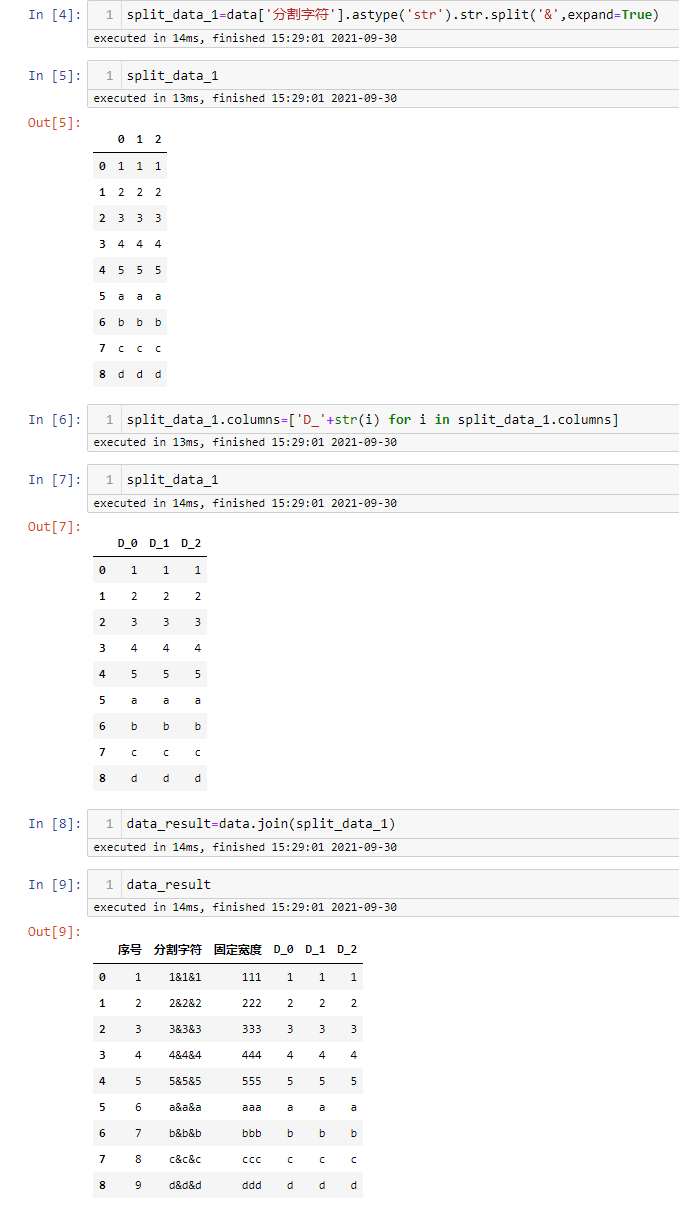
分割符号
固定宽度分列
pandas里面没有固定分割的相应函数,这里巧妙的运用了辅助函数来进行处理,这里的固定宽度为1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #定义个辅助函数def concat_split(x,width=1): result='' start=0 while True: s=str(x)[start:start+width] if s: result =result + s + '&' else: break start=start+width return result[:-1]#先利用辅助函数,再进行分割split_data_2=data['固定宽度'].map(concat_split).str.split('&',expand=True)#修改分割后的字段名称split_data_2.columns=['W_'+str(i) for i in split_data_2.columns]#与原始数据进行合并data_result=data.join(split_data_2) |
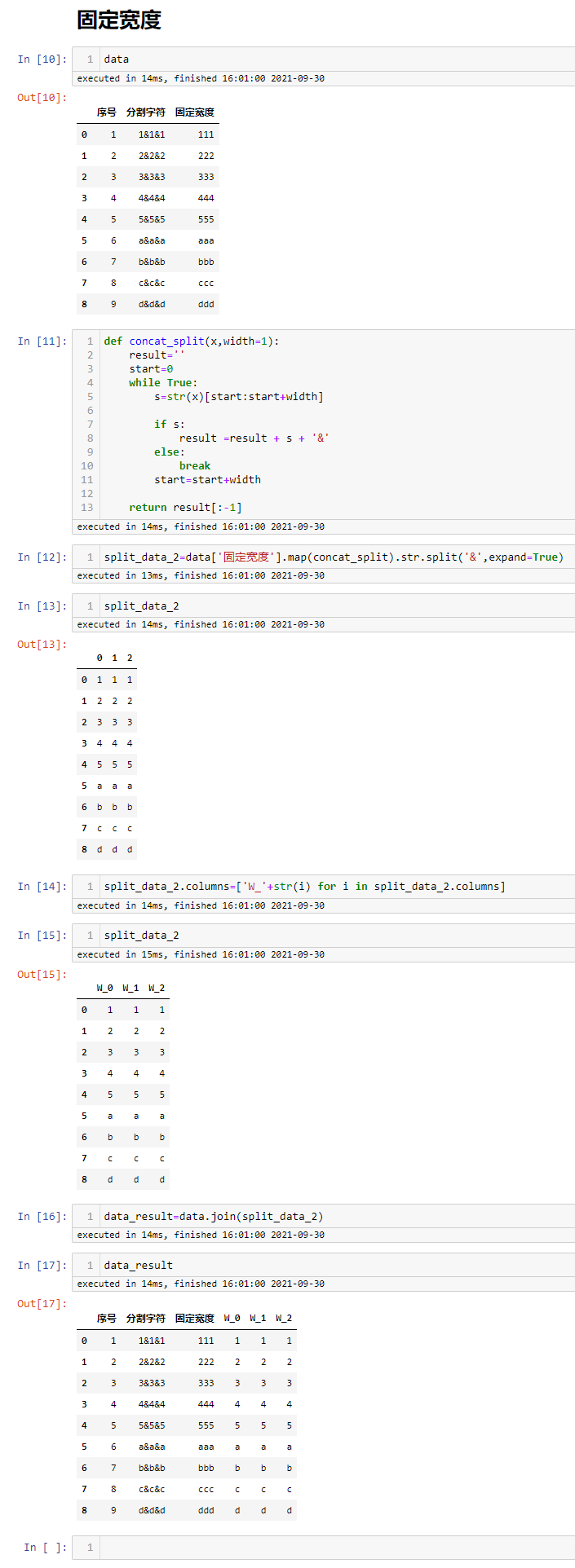
固定宽度
到此这篇关于pandas数据分列实现分割符号&固定宽度的文章就介绍到这了,更多相关pandas数据分列内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

