
引言
在做 pandas 数据处理的时候遇到了一个问题,获取到的数据总是会带有 dateframe 的格式,即总会有 index 显示出来。
为了去掉这些显示,我们可以使用 np.array() 函数进行数据类型的转换。
正文
比如,对于以下的数据形式:
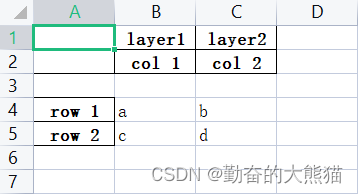
正常情况下,我们可以使用如下代码获取 layer1 对应的列数据:
1 2 3 4 5 6 7 8 9 10 | import pandas as pddata = pd.read_excel('output.xlsx')print(data['layer1'][2:])"""2 a3 cName: layer1, dtype: object""" |
可以看到,通过这种方式获取到的数据左侧会有 index 显示,末尾也会有 name 显示,为了不出现 index 和 name 这些不必要的额外信息,我们可以使用 np.array() 作用在 data['layer1'][2:] 上。
修改后得到的结果如下:
1 2 3 4 5 6 7 8 9 10 | import numpy as npimport pandas as pddata = pd.read_excel('output.xlsx')print(np.array(data['layer1'][2:]))"""result:['a' 'c']""" |
至此,我们说明了通过使用 np.array(),可以去掉数据中的 index 说明部分。
当然,我们也可以使用 pandas 中自带的 tolist() 方法去掉 index 部分。
1 2 3 4 5 6 7 8 | import pandas as pddata = pd.read_excel('output.xlsx')print(data['layer1'][2:].tolist())"""result:['a', 'c']""" |
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持IT俱乐部。

