
如何用SQL语言查询多个Excel表格
没错,之前我也不知道SQL语言除了可以查询(本文只讨论查询语句)数据库,还可以查询Excel,或者说经过一定处理后,可以像查询数据库一样查询Excel。
下面给出一个场景,假如你有几个(个数未知)Excel表格,你想在这些表格上实现SQL多表查询,该怎么办?
像这样:
| 学号 | 姓名 |
| 1054 | 小姜 |
| 1055 | 小王 |
| 1061 | 小李 |
| 1081 | 王哥 |
| 课程名称 | 任课老师 |
| 人工智能 | 王老师 |
| 数据库 | 李老师 |
| 运筹学 | 张老师 |
| 概率论 | 郝老师 |
| 学号 | 课程名称 | 分数 |
| 1054 | 人工智能 | 90 |
| 1055 | 数据库 | 91 |
| 1061 | 运筹学 | 92 |
| 1081 | 概率论 | 91 |
| 1054 | 运筹学 | 89 |
| 1055 | 概率论 | 91 |
| 1061 | 人工智能 | 95 |
| 1081 | 数据库 | 94 |
大致思路如下:
- 将所有要导入的Excel表放入一个.xlsx文件中,将各Sheet命名为表名,类似数据库的table名;
- 利用pandas库读取.xlsx文件并创建为一个ExcelFile类;
- 利用类中名为sheet_names的property获取其所有该文件所有的Sheet名;
- 用locals和read_excel函数创建名为各sheet名,值为各sheet内容的局部变量;
- 利用pandasql库中的sqldf来查询一个或多个dataframe,sqldf函数默认查询所有局部变量中的dataframe。
利用pandasql库中的sqldf来查询一个或多个dataframe,sqldf函数默认查询所有局部变量中的dataframe。
代码如下:
1 2 3 4 5 6 7 8 9 10 | import pandas as pdfrom pandasql import sqldfdef dealwith_excel(excel_file,sql_query): xls = pd.ExcelFile(excel_file) sheet_names = xls.sheet_names #list type # print(sheet_names) for sheet_name in sheet_names: locals()[sheet_name] = pd.read_excel(excel_file, sheet_name=sheet_name) df_result = sqldf(sql_query) return df_result |
最后返回的就是查询结果!
扩展:
如何使用sql查询excel内容
1. 简介
我们在前面的文章中提到了calcite支持csv和json文件的数据源适配, 其实就是将文件解析成表然后以文件夹为schema, 然后将生成的schema注册到RootSehema(RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下)下, 最终使用calcite的特性进行sql的解析查询返回.
但其实我们的数据文件一般使用excel进行存储,流转, 但很可惜, calcite本身没有excel的适配器, 但其实我们可以模仿calcite-file, 自己搞一个calcite-file-excel, 也可以熟悉calcite的工作原理.
2. 实现思路
因为excel有sheet的概念, 所以可以将一个excel解析成schema, 每个sheet解析成table, 实现步骤如下:
- 实现
SchemaFactory重写create方法: schema工厂 用于创建schema - 继承
AbstractSchema: schema描述类 用于解析excel, 创建table(解析sheet) - 继承
AbstractTable, ScannableTable: table描述类 提供字段信息和数据内容等(解析sheet data)
3. Excel样例
excel有两个sheet页, 分别是user_info 和 role_info如下:
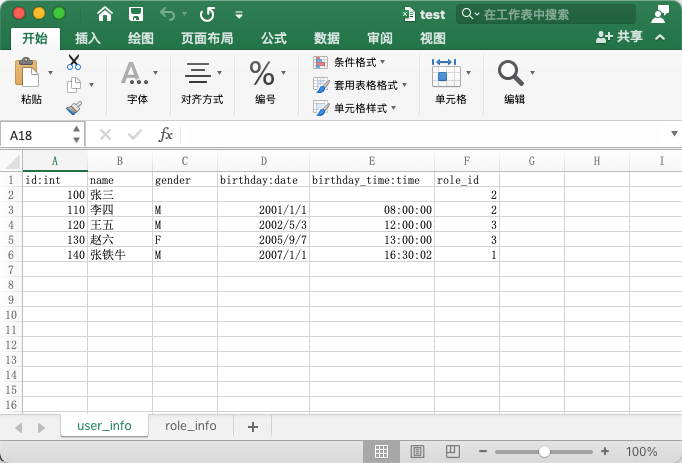

ok, 万事具备.
4. Maven
1 | org.apache.poipoi-ooxml5.2.3org.apache.poipoi5.2.3org.apache.calcitecalcite-core1.37.0 |
5. 核心代码
5.1 SchemaFactory
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | package com.ldx.calcite.excel;import com.google.common.collect.Lists;import org.apache.calcite.schema.Schema;import org.apache.calcite.schema.SchemaFactory;import org.apache.calcite.schema.SchemaPlus;import org.apache.commons.lang3.ObjectUtils;import org.apache.commons.lang3.StringUtils;import java.io.File;import java.util.List;import java.util.Map;/** * schema factory */public class ExcelSchemaFactory implements SchemaFactory { public final static ExcelSchemaFactory INSTANCE = new ExcelSchemaFactory(); private ExcelSchemaFactory(){} @Override public Schema create(SchemaPlus parentSchema, String name, Map operand) { final Object filePath = operand.get("filePath"); if (ObjectUtils.isEmpty(filePath)) { throw new NullPointerException("can not find excel file"); } return this.create(filePath.toString()); } public Schema create(String excelFilePath) { if (StringUtils.isBlank(excelFilePath)) { throw new NullPointerException("can not find excel file"); } return this.create(new File(excelFilePath)); } public Schema create(File excelFile) { if (ObjectUtils.isEmpty(excelFile) || !excelFile.exists()) { throw new NullPointerException("can not find excel file"); } if (!excelFile.isFile() || !isExcelFile(excelFile)) { throw new RuntimeException("can not find excel file: " + excelFile.getAbsolutePath()); } return new ExcelSchema(excelFile); } protected List supportedFileSuffix() { return Lists.newArrayList("xls", "xlsx"); } private boolean isExcelFile(File excelFile) { if (ObjectUtils.isEmpty(excelFile)) { return false; } final String name = excelFile.getName(); return StringUtils.endsWithAny(name, this.supportedFileSuffix().toArray(new String[0])); }} |
schema中有多个重载的create方法用于方便的创建schema, 最终将excel file 交给ExcelSchema创建一个schema对象
5.2 Schema
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | package com.ldx.calcite.excel;import org.apache.calcite.schema.Table;import org.apache.calcite.schema.impl.AbstractSchema;import org.apache.commons.lang3.ObjectUtils;import org.apache.poi.ss.usermodel.Sheet;import org.apache.poi.ss.usermodel.Workbook;import org.apache.poi.ss.usermodel.WorkbookFactory;import org.testng.collections.Maps;import java.io.File;import java.util.Iterator;import java.util.Map;/** * schema */public class ExcelSchema extends AbstractSchema { private final File excelFile; private Map tableMap; public ExcelSchema(File excelFile) { this.excelFile = excelFile; } @Override protected Map getTableMap() { if (ObjectUtils.isEmpty(tableMap)) { tableMap = createTableMap(); } return tableMap; } private Map createTableMap() { final Map result = Maps.newHashMap(); try (Workbook workbook = WorkbookFactory.create(excelFile)) { final Iterator sheetIterator = workbook.sheetIterator(); while (sheetIterator.hasNext()) { final Sheet sheet = sheetIterator.next(); final ExcelScannableTable excelScannableTable = new ExcelScannableTable(sheet, null); result.put(sheet.getSheetName(), excelScannableTable); } } catch (Exception ignored) {} return result; }} |
schema类读取Excel file, 并循环读取sheet, 将每个sheet解析成ExcelScannableTable并存储
5.3 Table
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 | package com.ldx.calcite.excel;import com.google.common.collect.Lists;import com.ldx.calcite.excel.enums.JavaFileTypeEnum;import org.apache.calcite.DataContext;import org.apache.calcite.adapter.java.JavaTypeFactory;import org.apache.calcite.linq4j.Enumerable;import org.apache.calcite.linq4j.Linq4j;import org.apache.calcite.rel.type.RelDataType;import org.apache.calcite.rel.type.RelDataTypeFactory;import org.apache.calcite.rel.type.RelProtoDataType;import org.apache.calcite.schema.ScannableTable;import org.apache.calcite.schema.impl.AbstractTable;import org.apache.calcite.sql.type.SqlTypeName;import org.apache.calcite.util.Pair;import org.apache.commons.lang3.ObjectUtils;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.Row;import org.apache.poi.ss.usermodel.Sheet;import org.checkerframework.checker.nullness.qual.Nullable;import java.util.List;/** * table */public class ExcelScannableTable extends AbstractTable implements ScannableTable { private final RelProtoDataType protoRowType; private final Sheet sheet; private RelDataType rowType; private List fieldTypes; private List<object data-origwidth="" data-origheight="" style="width: 1264px;"> rowDataList; public ExcelScannableTable(Sheet sheet, RelProtoDataType protoRowType) { this.protoRowType = protoRowType; this.sheet = sheet; } @Override public Enumerable scan(DataContext root) { JavaTypeFactory typeFactory = root.getTypeFactory(); final List fieldTypes = this.getFieldTypes(typeFactory); if (rowDataList == null) { rowDataList = readExcelData(sheet, fieldTypes); } return Linq4j.asEnumerable(rowDataList); } @Override public RelDataType getRowType(RelDataTypeFactory typeFactory) { if (ObjectUtils.isNotEmpty(protoRowType)) { return protoRowType.apply(typeFactory); } if (ObjectUtils.isEmpty(rowType)) { rowType = deduceRowType((JavaTypeFactory) typeFactory, sheet, null); } return rowType; } public List getFieldTypes(RelDataTypeFactory typeFactory) { if (fieldTypes == null) { fieldTypes = Lists.newArrayList(); deduceRowType((JavaTypeFactory) typeFactory, sheet, fieldTypes); } return fieldTypes; } private List<object data-origwidth="" data-origheight="" style="width: 512px;"> readExcelData(Sheet sheet, List fieldTypes) { List<object data-origwidth="" data-origheight="" style="width: 387px;"> rowDataList = Lists.newArrayList(); for (int rowIndex = 1; rowIndex fieldTypes) { final List names = Lists.newArrayList(); final List types = Lists.newArrayList(); if (sheet != null) { Row headerRow = sheet.getRow(0); if (headerRow != null) { for (int i = 0; i </object></object></object> |
table类中其中有两个比较关键的方法
scan: 扫描表内容, 我们这里将sheet页面的数据内容解析存储最后交给calcite
getRowType: 获取字段信息, 我们这里默认使用第一条记录作为表头(row[0]) 并解析为字段信息, 字段规则跟csv一样 name:string, 冒号前面的是字段key, 冒号后面的是字段类型, 如果未指定字段类型, 则解析为UNKNOWN, 后续JavaFileTypeEnum会进行类型推断, 最终在结果处理时calcite也会进行推断
deduceRowType: 推断字段类型, 方法中使用JavaFileTypeEnum枚举类对java type & sql type & 字段值转化处理方法 进行管理
5.4 ColumnTypeEnum
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 | package com.ldx.calcite.excel.enums;import lombok.Getter;import lombok.extern.slf4j.Slf4j;import org.apache.calcite.avatica.util.DateTimeUtils;import org.apache.calcite.sql.type.SqlTypeName;import org.apache.commons.lang3.ObjectUtils;import org.apache.commons.lang3.StringUtils;import org.apache.commons.lang3.time.FastDateFormat;import org.apache.poi.ss.usermodel.Cell;import org.apache.poi.ss.usermodel.DateUtil;import org.apache.poi.ss.util.CellUtil;import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Arrays;import java.util.Date;import java.util.Optional;import java.util.TimeZone;import java.util.function.Function;/** * type converter */@Slf4j@Getterpublic enum JavaFileTypeEnum { STRING("string", SqlTypeName.VARCHAR, Cell::getStringCellValue), BOOLEAN("boolean", SqlTypeName.BOOLEAN, Cell::getBooleanCellValue), BYTE("byte", SqlTypeName.TINYINT, Cell::getStringCellValue), CHAR("char", SqlTypeName.CHAR, Cell::getStringCellValue), SHORT("short", SqlTypeName.SMALLINT, Cell::getNumericCellValue), INT("int", SqlTypeName.INTEGER, cell -> (Double.valueOf(cell.getNumericCellValue()).intValue())), LONG("long", SqlTypeName.BIGINT, cell -> (Double.valueOf(cell.getNumericCellValue()).longValue())), FLOAT("float", SqlTypeName.REAL, Cell::getNumericCellValue), DOUBLE("double", SqlTypeName.DOUBLE, Cell::getNumericCellValue), DATE("date", SqlTypeName.DATE, getValueWithDate()), TIMESTAMP("timestamp", SqlTypeName.TIMESTAMP, getValueWithTimestamp()), TIME("time", SqlTypeName.TIME, getValueWithTime()), UNKNOWN("unknown", SqlTypeName.UNKNOWN, getValueWithUnknown()),; // cell type private final String typeName; // sql type private final SqlTypeName sqlTypeName; // value convert func private final Function cellValueFunc; private static final FastDateFormat TIME_FORMAT_DATE; private static final FastDateFormat TIME_FORMAT_TIME; private static final FastDateFormat TIME_FORMAT_TIMESTAMP; static { final TimeZone gmt = TimeZone.getTimeZone("GMT"); TIME_FORMAT_DATE = FastDateFormat.getInstance("yyyy-MM-dd", gmt); TIME_FORMAT_TIME = FastDateFormat.getInstance("HH:mm:ss", gmt); TIME_FORMAT_TIMESTAMP = FastDateFormat.getInstance("yyyy-MM-dd HH:mm:ss", gmt); } JavaFileTypeEnum(String typeName, SqlTypeName sqlTypeName, Function cellValueFunc) { this.typeName = typeName; this.sqlTypeName = sqlTypeName; this.cellValueFunc = cellValueFunc; } public static Optional of(String typeName) { return Arrays .stream(values()) .filter(type -> StringUtils.equalsIgnoreCase(typeName, type.getTypeName())) .findFirst(); } public static SqlTypeName findSqlTypeName(String typeName) { final Optional javaFileTypeOptional = of(typeName); if (javaFileTypeOptional.isPresent()) { return javaFileTypeOptional .get() .getSqlTypeName(); } return SqlTypeName.UNKNOWN; } public Object getCellValue(Cell cell) { return cellValueFunc.apply(cell); } public static Function getValueWithUnknown() { return cell -> { if (ObjectUtils.isEmpty(cell)) { return null; } switch (cell.getCellType()) { case STRING: return cell.getStringCellValue(); case NUMERIC: if (DateUtil.isCellDateFormatted(cell)) { // 如果是日期类型,返回日期对象 return cell.getDateCellValue(); } else { // 否则返回数值 return cell.getNumericCellValue(); } case BOOLEAN: return cell.getBooleanCellValue(); case FORMULA: // 对于公式单元格,先计算公式结果,再获取其值 try { return cell.getNumericCellValue(); } catch (Exception e) { try { return cell.getStringCellValue(); } catch (Exception ex) { log.error("parse unknown data error, cellRowIndex:{}, cellColumnIndex:{}", cell.getRowIndex(), cell.getColumnIndex(), e); return null; } } case BLANK: return ""; default: return null; } }; } public static Function getValueWithDate() { return cell -> { Date date = cell.getDateCellValue(); if(ObjectUtils.isEmpty(date)) { return null; } try { final String formated = new SimpleDateFormat("yyyy-MM-dd").format(date); Date newDate = TIME_FORMAT_DATE.parse(formated); return (int) (newDate.getTime() / DateTimeUtils.MILLIS_PER_DAY); } catch (ParseException e) { log.error("parse date error, date:{}", date, e); } return null; }; } public static Function getValueWithTimestamp() { return cell -> { Date date = cell.getDateCellValue(); if(ObjectUtils.isEmpty(date)) { return null; } try { final String formated = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(date); Date newDate = TIME_FORMAT_TIMESTAMP.parse(formated); return (int) newDate.getTime(); } catch (ParseException e) { log.error("parse timestamp error, date:{}", date, e); } return null; }; } public static Function getValueWithTime() { return cell -> { Date date = cell.getDateCellValue(); if(ObjectUtils.isEmpty(date)) { return null; } try { final String formated = new SimpleDateFormat("HH:mm:ss").format(date); Date newDate = TIME_FORMAT_TIME.parse(formated); return newDate.getTime(); } catch (ParseException e) { log.error("parse time error, date:{}", date, e); } return null; }; }} |
该枚举类主要管理了java type& sql type & cell value convert func, 方便统一管理类型映射及单元格内容提取时的转换方法(这里借用了java8 function函数特性)
注: 这里的日期转换只能这样写, 即使用GMT的时区(抄的
calcite-file), 要不然输出的日期时间一直有时差…
6. 测试查询
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 | package com.ldx.calcite;import com.ldx.calcite.excel.ExcelSchemaFactory;import lombok.SneakyThrows;import lombok.extern.slf4j.Slf4j;import org.apache.calcite.config.CalciteConnectionProperty;import org.apache.calcite.jdbc.CalciteConnection;import org.apache.calcite.schema.Schema;import org.apache.calcite.schema.SchemaPlus;import org.apache.calcite.util.Sources;import org.junit.jupiter.api.AfterAll;import org.junit.jupiter.api.BeforeAll;import org.junit.jupiter.api.Test;import org.testng.collections.Maps;import java.net.URL;import java.sql.Connection;import java.sql.DriverManager;import java.sql.ResultSet;import java.sql.ResultSetMetaData;import java.sql.SQLException;import java.sql.Statement;import java.util.Map;import java.util.Properties;@Slf4jpublic class CalciteExcelTest { private static Connection connection; private static SchemaPlus rootSchema; private static CalciteConnection calciteConnection; @BeforeAll @SneakyThrows public static void beforeAll() { Properties info = new Properties(); // 不区分sql大小写 info.setProperty(CalciteConnectionProperty.CASE_SENSITIVE.camelName(), "false"); // 创建Calcite连接 connection = DriverManager.getConnection("jdbc:calcite:", info); calciteConnection = connection.unwrap(CalciteConnection.class); // 构建RootSchema,在Calcite中,RootSchema是所有数据源schema的parent,多个不同数据源schema可以挂在同一个RootSchema下 rootSchema = calciteConnection.getRootSchema(); } @Test @SneakyThrows public void test_execute_query() { final Schema schema = ExcelSchemaFactory.INSTANCE.create(resourcePath("file/test.xlsx")); rootSchema.add("test", schema); // 设置默认的schema calciteConnection.setSchema("test"); final Statement statement = calciteConnection.createStatement(); ResultSet resultSet = statement.executeQuery("SELECT * FROM user_info"); printResultSet(resultSet); System.out.println("========="); ResultSet resultSet2 = statement.executeQuery("SELECT * FROM test.user_info where id > 110 and birthday > '2003-01-01'"); printResultSet(resultSet2); System.out.println("========="); ResultSet resultSet3 = statement.executeQuery("SELECT * FROM test.user_info ui inner join test.role_info ri on ui.role_id = ri.id"); printResultSet(resultSet3); } @AfterAll @SneakyThrows public static void closeResource() { connection.close(); } private static String resourcePath(String path) { final URL url = CalciteExcelTest.class.getResource("/" + path); return Sources.of(url).file().getAbsolutePath(); } public static void printResultSet(ResultSet resultSet) throws SQLException { // 获取 ResultSet 元数据 ResultSetMetaData metaData = resultSet.getMetaData(); // 获取列数 int columnCount = metaData.getColumnCount(); log.info("Number of columns: {}",columnCount); // 遍历 ResultSet 并打印结果 while (resultSet.next()) { final Map item = Maps.newHashMap(); // 遍历每一列并打印 for (int i = 1; i |
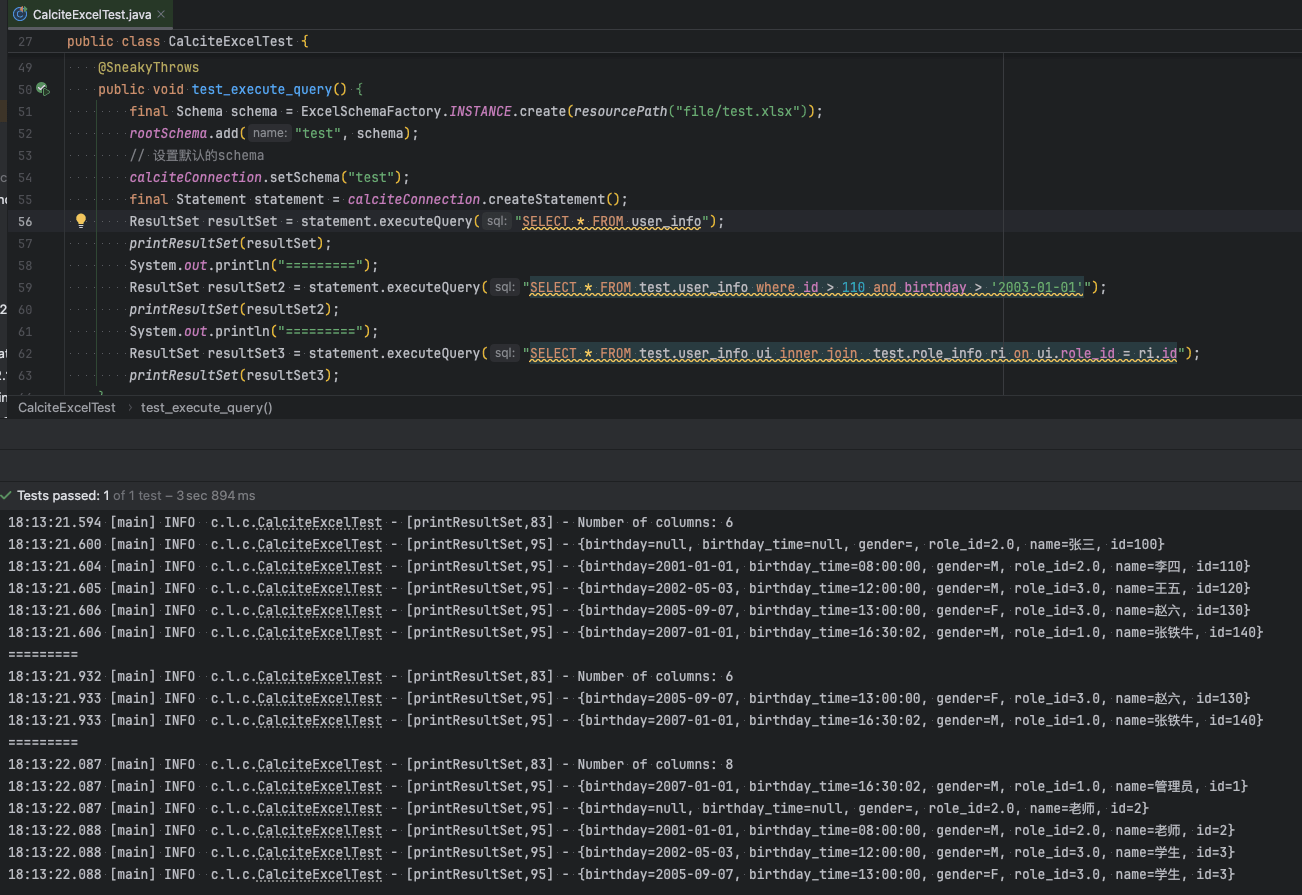
测试结果如下:
到此这篇关于使用SQL语言查询多个Excel表格的操作方法的文章就介绍到这了,更多相关SQL查询多个Excel表格内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

