
前引
相信大家 MySQL 都用了很久了,各种 join 查询天天都在写,但是 join 查询到底是怎么查的,怎么写才是最正确的,今天我就和大家一起学习探讨一下
索引对 join 查询的影响
数据准备
假设有两张表 t1、t2,两张表都存在有主键索引 id 和索引字段 a,b 字段无索引,然后在 t1 表中插入 100 行数据,t2 表中插入 1000 行数据进行实验
1 2 3 4 5 6 7 8 9 10 11 12 13 | CREATE TABLE `t2` ( `id` int NOT NULL, `a` int DEFAULT NULL, `b` int DEFAULT NULL, PRIMARY KEY (`id`), KEY `t2_a_index` (`a`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;CREATE PROCEDURE **idata**()BEGIN DECLARE i INT; SET i = 1; WHILE (i |
有索引查询过程
我们使用查询 SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a=t2.a);因为 join 查询 MYSQL 优化器不一定能按照我们的意愿去执行,所以为了分析我们选择用 STRAIGHT_JOIN 来代替,从而更直观的进行观察
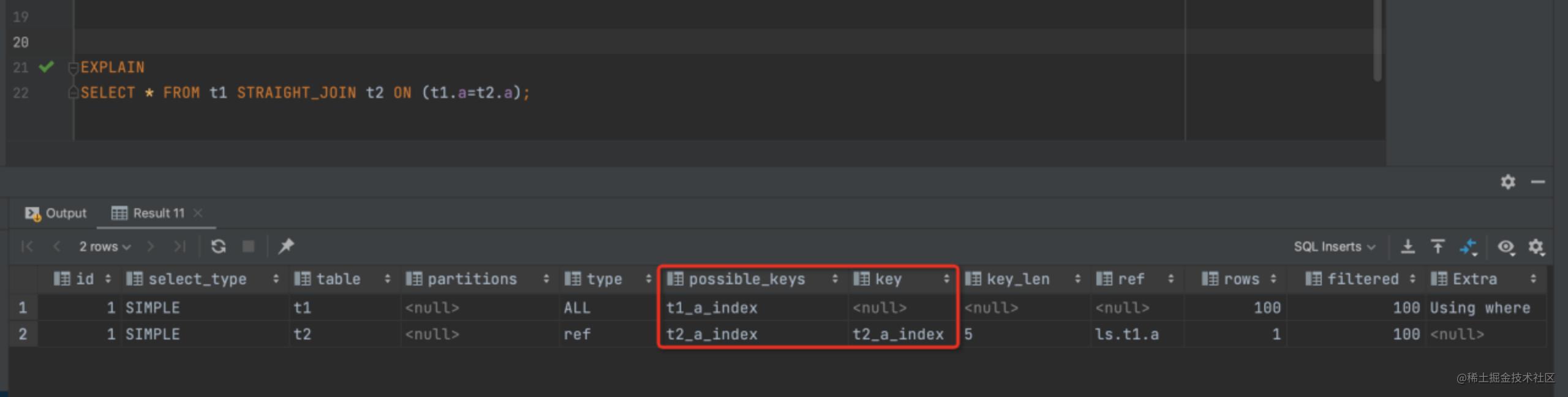
图 1
可以看出我们使用了 t1 作为驱动表,t2 作为被驱动表,上图的 explain 中显示本次查询用上了 t2 表的字段 a索引,所以这个语句的执行过程应该是下面这样的:
- 从 t1 表中读取一行数据 r
- 从数据 r中取出字段 a到表 t2 中进行匹配
- 取出 t2 表中符合条件的行,和 r组成一行作为结果集的一部分
- 重复执行步骤 1-3,直到表 t1 循环数据
该过程称之为 Index Nested-Loop Join,在这个流程里,驱动表 t1 进行了全表扫描,因为我们给 t1 表插入了 100 行数据,所以本次的扫描行数是 100,而进行 join 查询时,对于 t1 表的每一行都需去 t2 表中进行查找,走的是索引树搜索,因为我们构造的数据都是一一对应的,所以每次搜索只扫描一行,也就是 t2 表也是总共扫描 100 行,整个查询过程扫描的总行数是 100+100=200 行。
无索引查询过程
1 | SELECT * FROM t1 STRAIGHT_JOIN t2 ON (t1.a = t2.b); |
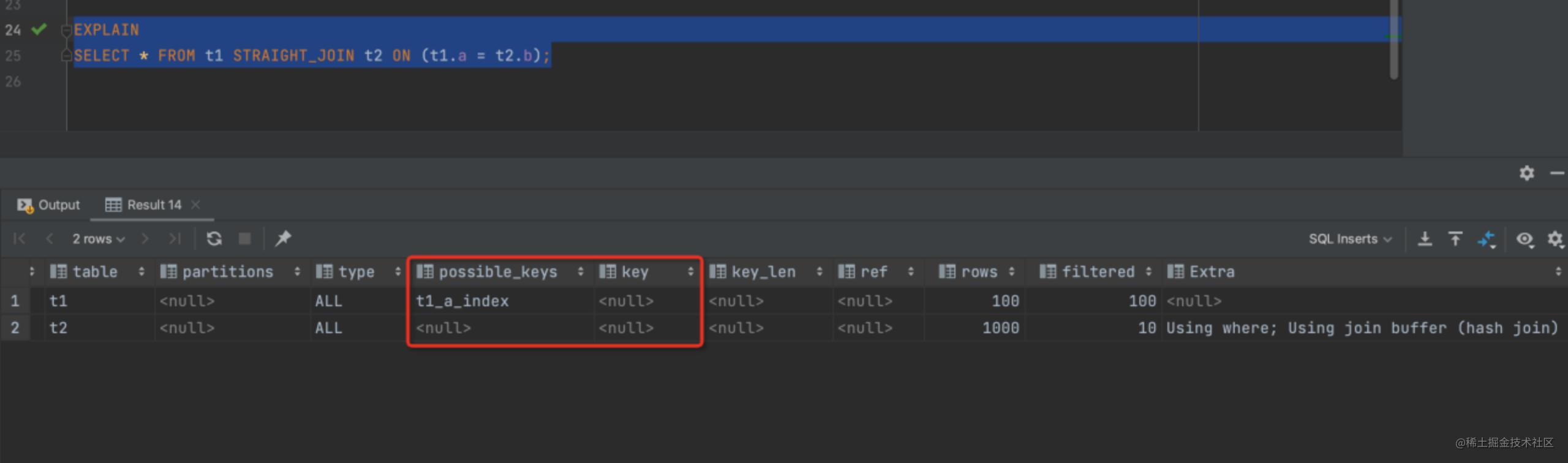
图 2
可以看出由于 t2 表字段 B上没有索引,所以按照上述 SQL 执行时每次从 t1 去匹配 t2 的时候都要做一次全表扫描,这样算下来扫描 t2 多大 100 次,总扫描次数就是 100*1000 = 10 万行。
当然了这个查询结果还是在我们建的这两个都是小表的情况下,如果是数量级 10 万行的表,就需要扫描 100 亿行,这就太恐怖了!
了解 Block Nested-Loop Join
Block Nested-Loop Join查询过程
那么被驱动表上没有存在索引,这一切都是怎么发生的呢?
实际上当被驱动表上没有可用的索引,算法流程是这样的:
- 把 t1 的数据读取线程内存 join_buffer 中,因为上述我们写的是 select * from,所以相当于是把整个 t1 表放入了内存;
- 扫描 t2 的过程,实际上是把 t2 的每一行取出来,跟 join_buffer 中的数据去做对比,满足 join 条件的,作为结果集的一部分进行返回。
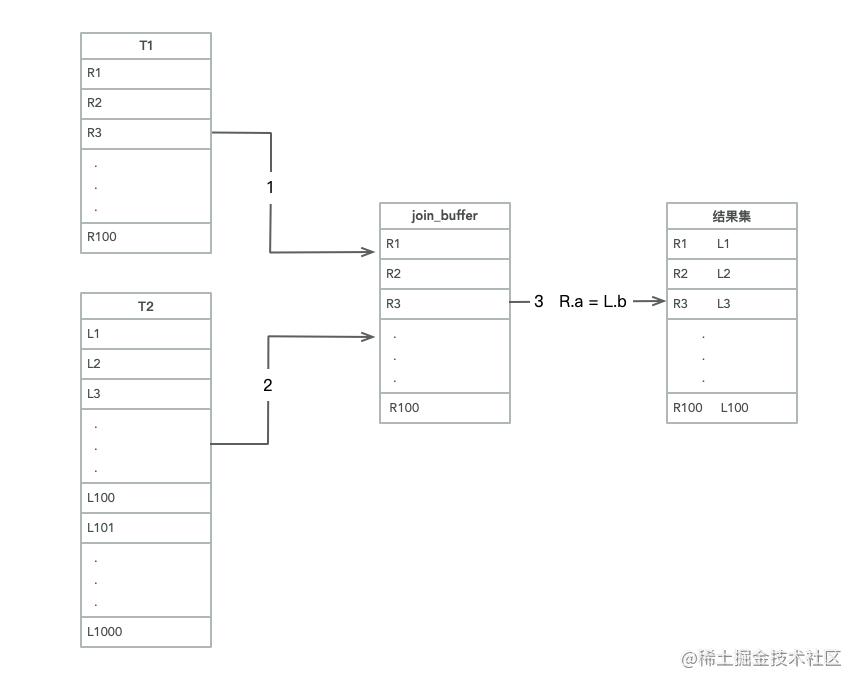
所以结合图 2中 Extra 部分说明 Using join buffer 可以发现这一丝端倪,整个过程中,对表 t1 和t2 都做了一次全表扫描,因此扫描的行数是 100+1000=1100 行,因为 join_buffer 是以无序数组的方式组织的,因此对于表 t2 中每一行,都要做 100 次判断,总共需要在内存中进行的判断次数是 100*1000=10 万次,但是因为这 10 万次是发生在内存中的所以速度上要快很多,性能也更好。
Join_buffer
根据上述已经知道了,没有索引的情况下 MySQL 是将数据读取内存进行循环判断的,那么这个内存肯定不是无限制让你使用的,这时我们就需要用到一个参数 join_buffer_size,该值默认大小 256k,如下图:
1 | SHOW VARIABLES LIKE '%join_buffer_size%'; |
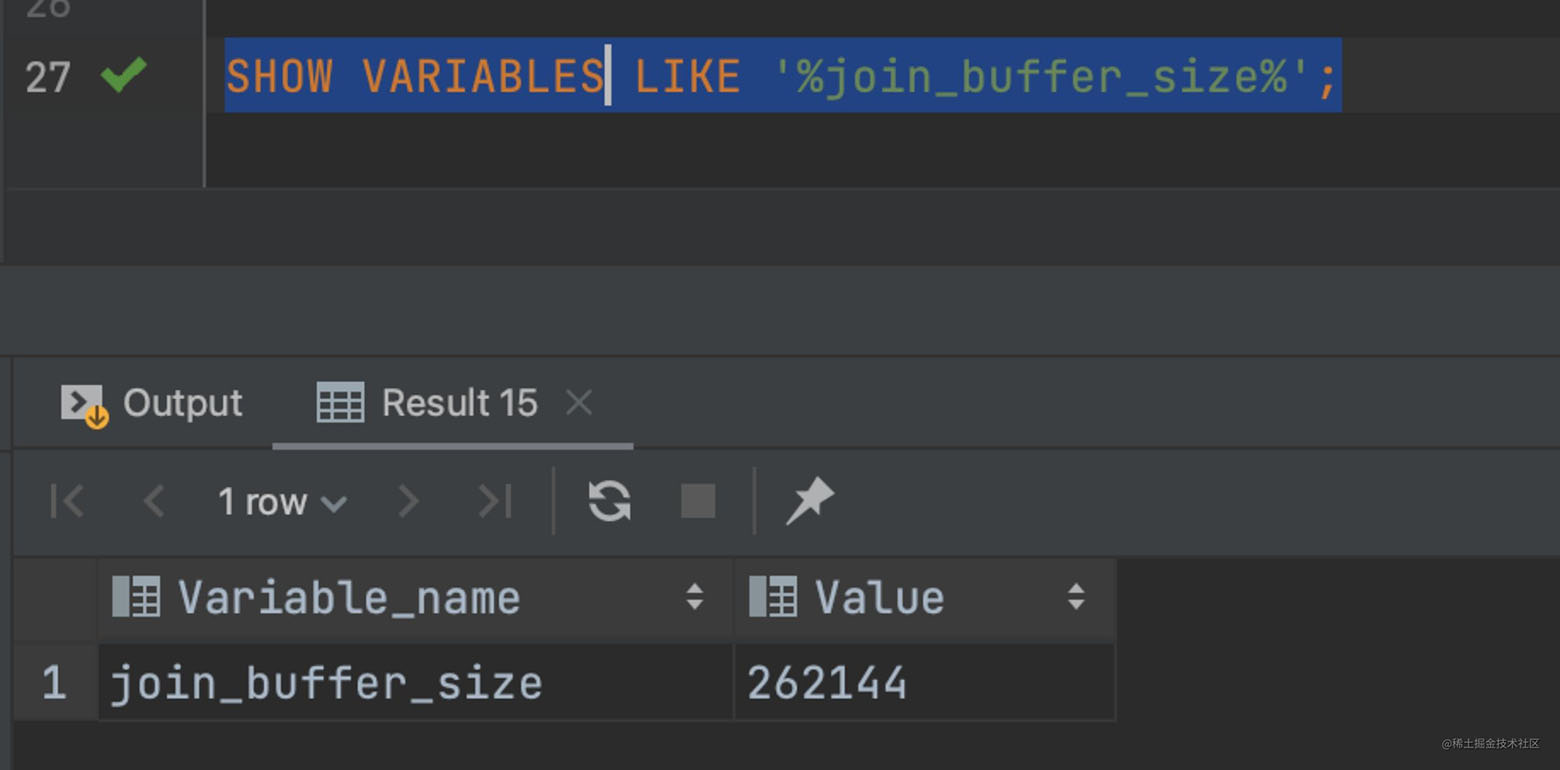
图 4
假如查询的数据过大一次加载不完,只能够加载部分数据(80 条),那么查询的过程就变成了下面这样
- 扫描表 t1,顺序读取数据行放入 join_buffer 中,直至加载完第 80 行满了
- 扫描表 t2,把 t2 表中的每一行取出来跟 join_buffer 中的数据做对比,将满足条件的数据作为结果集的一部分返回
- 清空 join_buffer
- 继续扫描表 t1,顺序读取剩余的数据行放入 join_buffer 中,执行步骤 2
这个流程体现了算法名称中 Block 的由来,分块 join,可以看出虽然查询过程中 t1 被分成了两次放入 join_buffer 中,导致 t2 表被扫描了 2次,但是判断等值条件的次数还是不变的,依然是(80+20)*1000=10 万次。
所以这就是有时候 join 查询很慢,有些大佬会让你把 join_buffer_size 调大的原因。
如何正确的写出 join 查询
驱动表的选择
- 有索引的情况下
在这个 join 语句执行过程中,驱动表是走全表扫描,而被驱动表是走树搜索。
假设被驱动表的行数是 M,每次在被驱动表查询一行数据,先要走索引 a,再搜索主键索引。每次搜索一棵树近似复杂度是以 2为底的 M的对数,记为 log2M,所以在被驱动表上查询一行数据的时间复杂度是 2*log2M。
假设驱动表的行数是 N,执行过程就要扫描驱动表 N 行,然后对于每一行,到被驱动表上 匹配一次。因此整个执行过程,近似复杂度是 N + N2log2M。显然,N 对扫描行数的影响更大,因此应该让小表来做驱动表。
- 那没有索引的情况
上述我知道了,因为 join_buffer 因为存在限制,所以查询的过程可能存在多次加载 join_buffer,但是判断的次数都是 10 万次,这种情况下应该怎么选择?
假设,驱动表的数据行数是 N,需要分 K 段才能完成算法流程,被驱动表的数据行数是 M。这里的 K不是常数,N 越大 K就越大,因此把 K 表示为λ*N,显然λ的取值范围 是 (0,1)。
扫描的行数就变成了 N+λNM,显然内存的判断次数是不受哪个表作为驱动表而影响的,而考虑到扫描行数,在 M和 N大小确定的情况下,N 小一些,整个算是的结果会更小,所以应该让小表作为驱动表
总结:真相大白了,不管是有索引还是无索引参与 join 查询的情况下都应该是使用小表作为驱动表。
什么是小表
还是以上面表 t1 和表 t2 为例子:
1 | SELECT * FROM t1 STRAIGHT_JOIN t2 ON t1.b = t2.b WHERE t2.id |
上面这两条 SQL 我们加上了条件 t2.id
再看另一组:
1 | SELECT t1.b,t2.* FROM t1 STRAIGHT_JOIN t2 ON t1.b = t2.b WHERE t2.id |
这个例子里,表 t1 和 t2 都是只有 100 行参加 join。 但是,这两条语句每次查询放入 join_buffer 中的数据是不一样的: 表 t1 只查字段 b,因此如果把 t1 放到 join_buffer 中,只需要放入字段 b 的值; 表 t2 需要查所有的字段,因此如果把表 t2 放到 join_buffer 中的话,就需要放入三个字 段 id、a 和 b。
这里,我们应该选择表 t1 作为驱动表。也就是说在这个例子里,”只需要一列参与 join 的 表 t1“是那个相对小的表。
结论:
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过 滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”, 应该作为驱动表。
到此这篇关于MySQL中join查询的文章就介绍到这了,更多相关MySQL join查询内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

