
一、row_number() 函数
在前面使用rownum实现分页,虽然是可以实现的,但是看似是否有点别扭。因为当需要对分页排序时,rownum总是先生成序列号再排序,其实这不时我们想要的。而row_number()函数则是先排序,再生成序列号。这也是row_number与rownum主要的区别。下面来看row_number()的使用:
语法:row_number() over([partition by col1] order by col2 [ASC | DESC] [,col3 [ASC | DESC]]…)
参数解释:
row_number() over():是固定写法,即不能单独使用row_nubmer()函数;
partition by:可选的。用于指定分组(或分开依据)的列,类似SELECT中的group by子句;
order by:用于指定排序的列,类似SELECT中的order by子句。
1.基本用法
1 | SELECTrow_number()over(orderbyempno)ASrnum,t1.*FROMemp t1; |
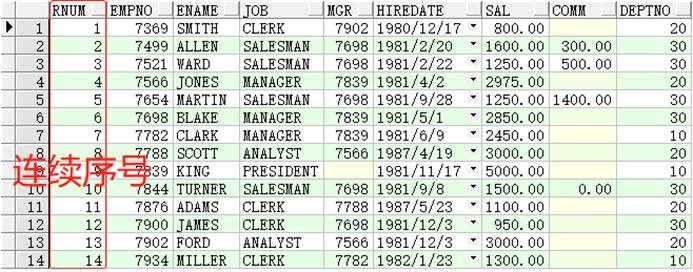
2.使用row_number()分页
1 2 3 | SELECT * FROM ( SELECT row_number() over(order by empno) AS rnum, t1.* FROM emp t1) t WHERE t.rnum BETWEEN 4 AND 6; |

3.使用partition by参数分区生成序号
当使用partition by参数时,序号将可能不是唯一的,因为序号的生成只会在当前分区中唯一,下一个分区又将从1开始计算,例如:
1 | SELECTrow_number()over(partitionbydeptnoorderbyempno)ASrnum,t1.*FROMemp t1; |

二、 rank()与dense_rank()函数
rank()与row_number()的区别在于,rank()会按照排序值相同的为一个序号(以下称为:块),第二个不同排序值将显示所有行的递增值,而不是当前序号加1。看示例:
1 | SELECTrank()over(orderbyjob)rnum,job,enameFROMemp t1; |
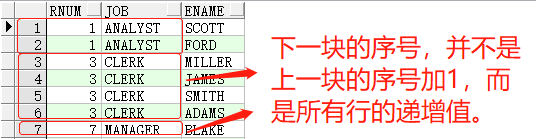
而dense_rank()函数,与rank()区别在于,第二个不同排序值,是对当前序号值加1,看示例:
1 | SELECTdense_rank()over(orderbyjob)rnum,job,enameFROMemp t1; |
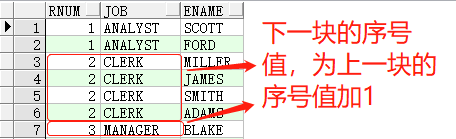
当指定partition by参数时,将根据指定的字段分组,进行分组计算序号值,序号值只在当前分组中有效,例如:
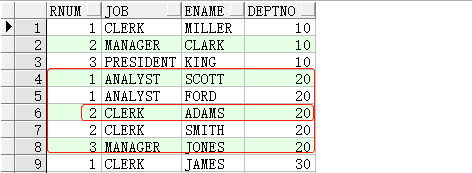
1 | SELECTrank()over(partitionbydeptnoorderbyjob)rnum,job,ename,deptnoFROMemp t1; |
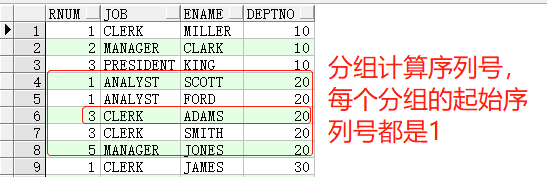
1 | SELECTdense_rank()over(partitionbydeptnoorderbyjob)rnum,job,ename,deptnoFROMemp t1; |
三、 over()函数结合聚合函数的使用
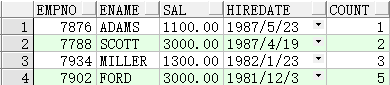
1 | SELECTempno,ename,sal,hiredate,COUNT(sal)OVER(ORDERBYhiredateDESC)countFROMemp; |
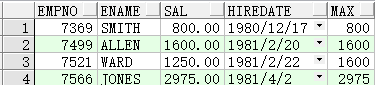
1 | SELECTempno,ename,sal,hiredate,MAX(sal)OVER(ORDERBYhiredateASC)maxFROMemp; |
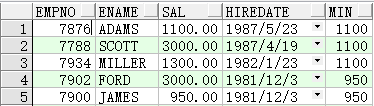
1 | SELECTempno,ename,sal,hiredate,MIN(sal)OVER(ORDERBYhiredateDESC)minFROMemp; |
1 | SELECTempno,ename,sal,hiredate,AVG(sal)OVER(ORDERBYhiredateDESC)avgFROMemp; |

1 | SELECTempno,ename,sal,hiredate,SUM(sal)OVER(ORDERBYhiredateDESC)sumFROMemp; |

四、 综合案例
1)查询前100条记录
1 | SELECT*FROMempWHERErownum |
注意:如果以上语句需要排序后再筛选,并不是能使用rownum实现,而需要使用row_number()函数。
2)查出4 ~ 6条的记录,并按员工编号排序(分页运用)
1 2 | SELECT*FROM(SELECTrow_number()over(orderbyempno)rnum,t.*FROMemp t)tWHEREt.rnum>=4ANDt.rnum |

3)查出每个部门工资最高的员工
1 | SELECT*FROM(SELECTrow_number()over(partitionbydeptnoorderbysalDESC)rnum,t.*FROMemp t)tWHEREt.rnum=1; |

4)查出每个部门工资最高的所有员工(排名并列的)
1 | SELECT*FROM(SELECTrank()over(partitionbydeptnoorderbysalDESC)rnum,t.*FROMemp t)tWHEREt.rnum=1; |

5)查出每个部门工资排名第三的所有员工(排名并列的)
1 | SELECT*FROM(SELECTdense_rank()over(partitionbydeptnoorderbysalASC)rnum,t.*FROMemp t)tWHEREt.rnum=3; |

注意:如果使用rank()是不行的,因为20号部门并列第二的员工有2个,序号3就被跳掉了,直接跳到了序号4,使用以下语句可以查看到:
1 | SELECTrank()over(partitionbydeptnoorderbysalASC)rnum,t.*FROMemp t; |

所以,使用rank()将会得到错误的结果:
1 | SELECTrank()over(partitionbydeptnoorderbysalASC)rnum,t.*FROMemp t; |

五、 总结
1.如果需要取前多少条记录,就使用rownum伪列。rownum就类似于SQL Server TOP子句的用法,但是rownum不能用于排序并过滤的场合
2.如果取多少条到多少条的记录(分页),就是使用row_number()函数。
例如:查出4 ~ 6条的记录,并按员工编号排序
3.如果取某个组别中最大值记录或最小值的记录,也可以使用row_number()函数,并结合partition by参数。
例如:查出每个部门工资最高的员工。
4.如果取某个组别中并列最大值或最小值得记录,就使用rank()函数,并结合partition by参数。
例如:查出每个部门工资最高的所有员工。
5.如果取某个组别中并列排名几记录,就使用dense_rank()函数,并结合partition by参数。
例如:查出每个部门工资排名第三的所有员工。

到此这篇关于Oracle 中 row_number()、rank()、dense_rank() 函数的用法的文章就介绍到这了,更多相关Oracle row_number()、rank()、dense_rank() 函数内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

