介绍
计数器大量应用于互联网上大大小小的项目,你可以在很多场景都能找到计数器的应用范畴,单纯以技术派项目为例,也有相当多的地方会有计数相关的诉求,比如
- 文章带赞数
- 收藏数
- 评论数
- 用户粉丝数
- ……
技术派中有两种查询计数相关的方案,一个是基于db中的操作记录进行实施,一种是基于redis的incr特性来实现计数器
下面来看一下,redis的计数器是怎样用于技术派的技术场景的
计数的业务场景
首先我们看一下技术派中使用到的计数器的场景,主要有两大类(业务计数+pv/uv),三个细分领域(用户、文章、站点)
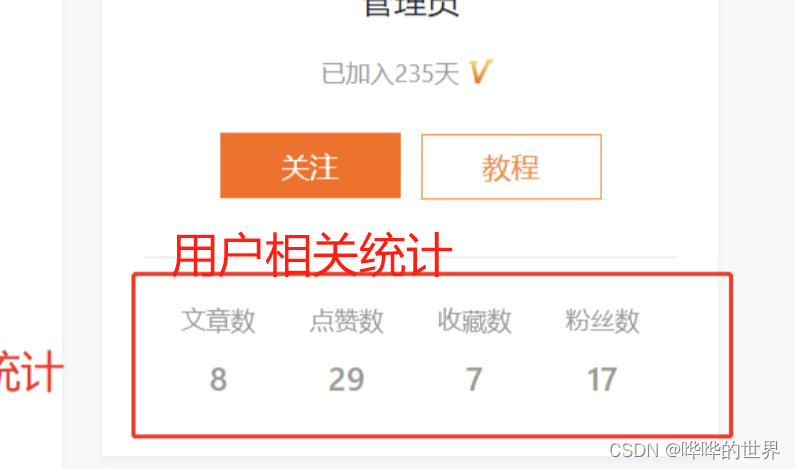
用户的相关统计信息
- 文章数,文章总阅读数,粉丝数,关注作者数,文章被收藏数、被点赞数量
站点的pv/uv等统计信息
- 网站的总pv/uv,某一天的pv/uv
- 某个uri的pv/uv

注意上面的几个场景,这里主要介绍redis计数器的使用
那用户与文章的相关统计将是我们的重点,因为这两个的业务属性很相似,因此我们选择一个重点,以用户统计来实现。
redis计数器
redis计数器,主要是借助原生的incr指令来实现原子的+1-1操作,更棒的是不仅redis的string数据结构支持incr,hash、zset数据结构同样也是支持incr的
1.incr指令
Redis incr命令将key中存储的数字值增值一。
- 如果key不存在,那么key的值会先被初始化为0,然后在执行INCR操作。
- 如果值包含错误类型,或者字符串类型的值不能表示为数字,那么返回一个错误。
- 本操作的值限制在64位有符号数字表示之内。
接下来看项目封装实现
/**
* 自增
*
* @param key
* @param filed
* @param cnt
* @return
*/
public static Long hIncr(String key, String filed, Integer cnt) {
return template.execute((RedisCallback) con -> con.hIncrBy(keyBytes(key), valBytes(filed), cnt));
}
2.用户计数统计
我们将用户的相关计数,每个用户对应一个hash数据结构
key: user_statistic_${userId}
filed:
- follCount: 关注数
- fansCount: 粉丝数
- articleCount: 已发布文章数
- praiseCount: 文章点赞数
- readCount: 文章被阅读数
- collectionCount: 文章被收藏数
计数器的核心就在于满足条件之后,实现的计数 + 1 / -1
通常的业务场景中,此类计数不太建议直接与业务代码强耦合,举个例子
用户收藏了一篇文章,若按照正常的设计,就是在收藏这里,带哦用计数器执行 + 1 操作
上面这样实现有问题吗?
显然是没有额问题的,但是不够好,不够优雅。
比如现在技术派的场景中,点赞之后,除了计数器更新之外,还有前面用户说到的用户活跃度更新,若所有的逻辑都放在业务中,会导致业务的耦合较重
技术派选择消息机制来应对这种场景(大一点的项目会设计自己额的消息总线,为了让各自的业务逻辑内聚,向外抛出自己额的状态/业务变更消息,实现解耦)
对映的,计数实现逻辑在。src/main/java/com/github/paicoding/forum/service/statistics/listener/UserStatisticEventListener.java
package com.github.paicoding.forum.service.statistics.listener;
import com.github.paicoding.forum.api.model.enums.ArticleEventEnum;
import com.github.paicoding.forum.api.model.event.ArticleMsgEvent;
import com.github.paicoding.forum.api.model.vo.notify.NotifyMsgEvent;
import com.github.paicoding.forum.core.cache.RedisClient;
import com.github.paicoding.forum.service.article.repository.dao.ArticleDao;
import com.github.paicoding.forum.service.article.repository.entity.ArticleDO;
import com.github.paicoding.forum.service.comment.repository.entity.CommentDO;
import com.github.paicoding.forum.service.user.repository.entity.UserFootDO;
import com.github.paicoding.forum.service.user.repository.entity.UserRelationDO;
import com.github.paicoding.forum.service.statistics.constants.CountConstants;
import org.springframework.context.event.EventListener;
import org.springframework.scheduling.annotation.Async;
import org.springframework.stereotype.Component;
import javax.annotation.Resource;
/**
* 用户活跃相关的消息监听器
*
* @author YiHui
* @date 2023/8/19
*/
@Component
public class UserStatisticEventListener {
@Resource
private ArticleDao articleDao;
/**
* 用户操作行为,增加对应的积分
*这段代码是一个使用Spring框架的事件监听器注解。
* 它使用了@EventListener注解来指定要监听的事件类型为NotifyMsgEvent.class,并且使用了@Async注解来表示该方法是异步执行的。
*
* 当NotifyMsgEvent事件被发布时,该事件监听器方法将被自动调用。由于使用了@Async注解,
* 该方法将在单独的线程中异步执行,不会阻塞主线程。
* @param msgEvent
*/
@EventListener(classes = NotifyMsgEvent.class)
@Async
public void notifyMsgListener(NotifyMsgEvent msgEvent) {
switch (msgEvent.getNotifyType()) {
//评论/回复
case COMMENT:
case REPLY:
CommentDO comment = (CommentDO) msgEvent.getContent();
RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + comment.getArticleId(), CountConstants.COMMENT_COUNT, 1);
break;
//删除评论/回复
case DELETE_COMMENT:
case DELETE_REPLY:
comment = (CommentDO) msgEvent.getContent();
RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + comment.getArticleId(), CountConstants.COMMENT_COUNT, -1);
break;
//收藏
case COLLECT:
UserFootDO foot = (UserFootDO) msgEvent.getContent();
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.COLLECTION_COUNT, 1);
RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.COLLECTION_COUNT, 1);
break;
//取消收藏
case CANCEL_COLLECT:
foot = (UserFootDO) msgEvent.getContent();
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.COLLECTION_COUNT, -1);
RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.COLLECTION_COUNT, -1);
break;
//点赞
case PRAISE:
foot = (UserFootDO) msgEvent.getContent();
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.PRAISE_COUNT, 1);
RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.PRAISE_COUNT, 1);
break;
//取消点赞
case CANCEL_PRAISE:
foot = (UserFootDO) msgEvent.getContent();
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + foot.getDocumentUserId(), CountConstants.PRAISE_COUNT, -1);
RedisClient.hIncr(CountConstants.ARTICLE_STATISTIC_INFO + foot.getDocumentId(), CountConstants.PRAISE_COUNT, -1);
break;
case FOLLOW:
UserRelationDO relation = (UserRelationDO) msgEvent.getContent();
// 主用户粉丝数 + 1
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getUserId(), CountConstants.FANS_COUNT, 1);
// 粉丝的关注数 + 1
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getFollowUserId(), CountConstants.FOLLOW_COUNT, 1);
break;
case CANCEL_FOLLOW:
relation = (UserRelationDO) msgEvent.getContent();
// 主用户粉丝数 + 1
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getUserId(), CountConstants.FANS_COUNT, -1);
// 粉丝的关注数 + 1
RedisClient.hIncr(CountConstants.USER_STATISTIC_INFO + relation.getFollowUserId(), CountConstants.FOLLOW_COUNT, -1);
break;
default:
}
}
/**
* 发布文章,更新对应的文章计数
*
* @param event
*/
@Async
@EventListener(ArticleMsgEvent.class)
public void publishArticleListener(ArticleMsgEvent event) {
ArticleEventEnum type = event.getType();
if (type == ArticleEventEnum.ONLINE || type == ArticleEventEnum.OFFLINE || type == ArticleEventEnum.DELETE) {
Long userId = event.getContent().getUserId();
int count = articleDao.countArticleByUser(userId);
RedisClient.hSet(CountConstants.USER_STATISTIC_INFO + userId, CountConstants.ARTICLE_COUNT, count);
}
}
}
上面直接基于当下技术派抛出的各种消息事件,来实现用户/文章对应计数变更
不一样的地方则在于用户的文章数统计,因为消息发布时,并没有告知这个文章是 从 未上线状态到发布, 发布到下线/删除 ,因此无法进行+1 -1。我们直接采用的是全量的更新策略。
注:
全量更新策略指的是**在数据同步或更新过程中,每次都对整个数据集进行处理,而不是只更新发生变化的部分**。
这种策略的优点包括:
– **简单直观**:由于不需要考虑数据的增量变化,因此实现起来相对简单,易于理解和操作。
– **数据一致性**:每次全量更新可以确保目标系统中的数据与源系统保持完全一致,避免了因部分更新而导致的数据不一致问题。然而,全量更新策略也存在一些缺点:
– **资源消耗大**:当数据量庞大或者更新频率较高时,全量更新可能会占用大量的网络带宽和存储资源,导致效率低下。
– **系统压力大**:频繁的全量更新可能会给系统带来较大的处理压力,尤其是在数据量持续增长的情况下,可能会超出系统的处理能力。此外,在某些情况下,全量更新策略可能不是最佳选择。例如,在数据仓库中,如果源数据库的数据量非常大,而且只有少量数据发生变更,使用全量更新策略就不如增量更新策略高效。增量更新策略只针对发生变化的数据进行处理,这样可以大大减少数据处理的工作量和系统资源的消耗。
总的来说,全量更新策略适用于数据量较小或更新频率较低的场景,而在数据量大且更新频繁的环境中,可能需要考虑其他更高效的数据更新策略。在实际应用中,应根据具体的业务需求和系统条件来选择合适的更新策略。
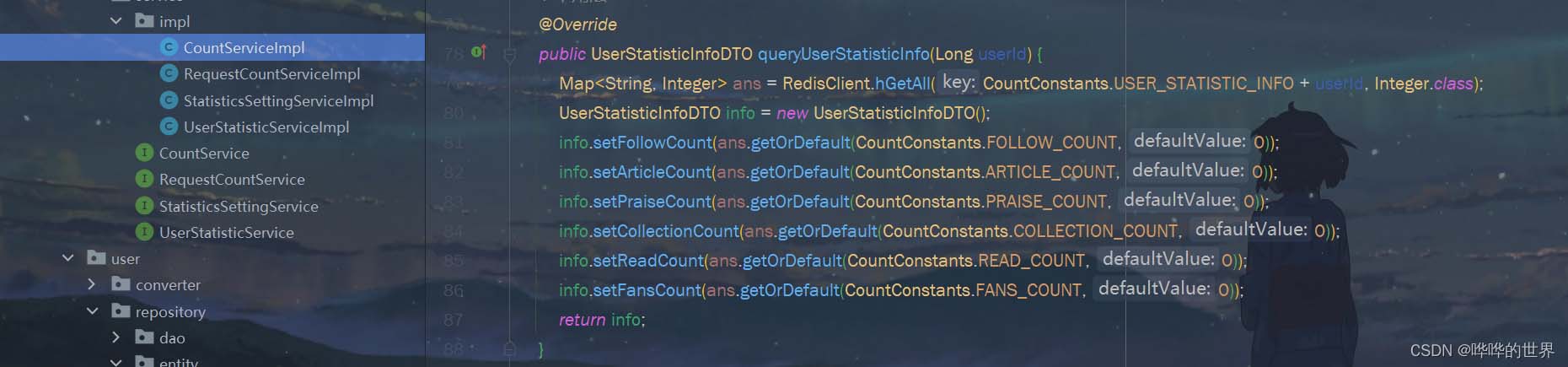
3.用户统计信息查询
前面实现了用户的相关统计数,查询用户的统计信息则相对简单了,直接hgetall即可。
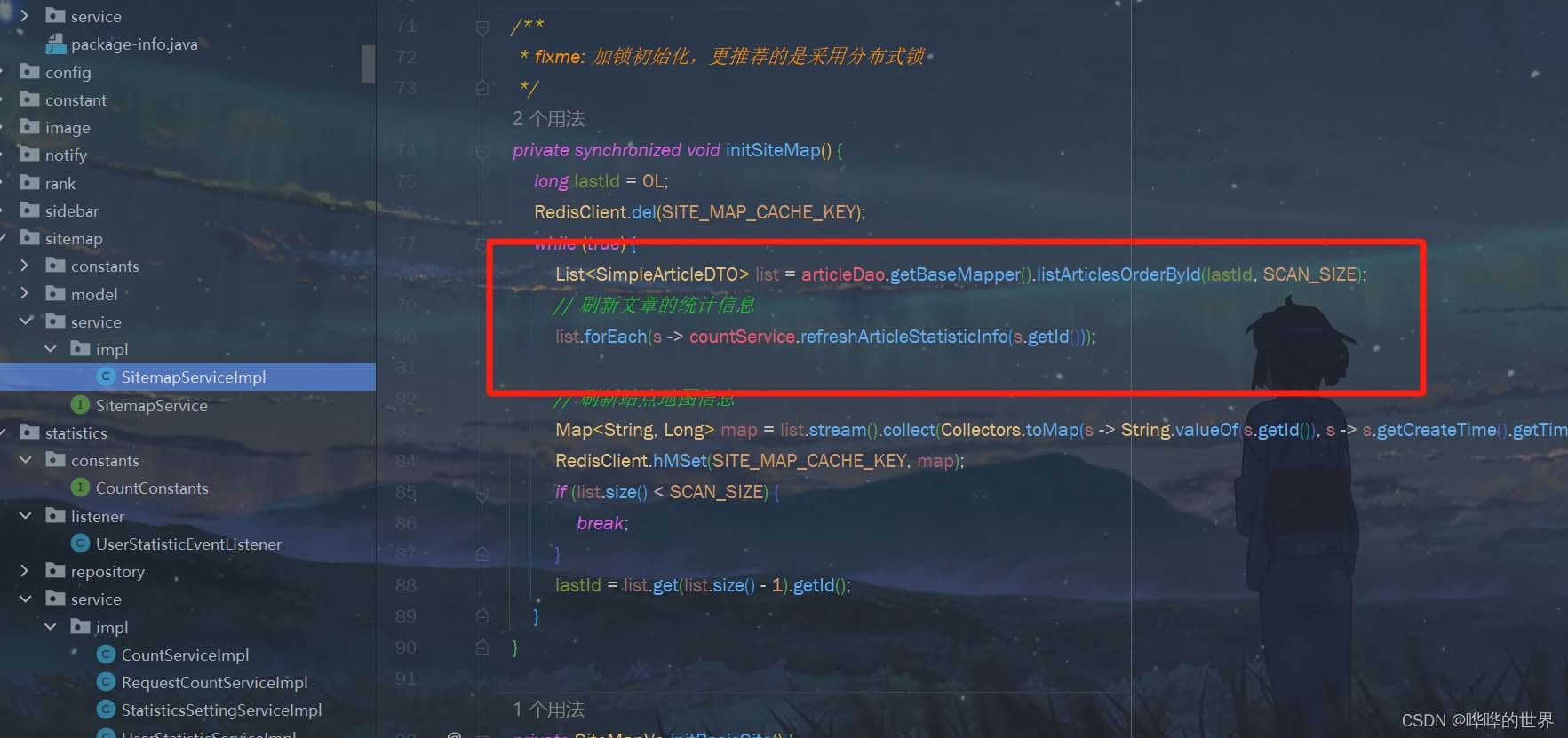
4.缓存一致性
基本上到上面,一个完整的计数服务就已经成型了,但是我们在实际的生产服务中,再自信的人也不保证它没问题100分。
通常我们会做一个校对/定时同步任务来保证缓存与实际数据中的一致性
技术派中选择简单的定时同步方案来实现
- 用户统计信息每天全量同步

- 文章统计信息每天全量同步
总结
基于redis的incr ,很容易就可以实现计数相关的需求支撑,但是为啥我们要用redis来实现一个计数器呢?直接用数据库的原始数据进行统计有什么问题吗?
通常而言,项目初期,或者项目本身非常简单,访问量低,只希望快速上线支撑业务时,使用db进行统计即可,优势时简单,叙述,不容易出问题;缺点则是每次都是实时统计性能差,扩展性不强。
当我们项目发展起来,借助redis直接存储最终结果。再展示层直接俄获取即可,性能更强,满足高并发,缺点是数据的一致性保障难度高。先选择一个实现代价小的,再重构哈啊哈哈。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持IT俱乐部。

