在计算字符数时,一般情况下,英文字符、数字和大部分符号都可以被视为占一个字符长度,因为它们是单个字节。然而,对于某些特殊字符,如表情符号和部分非英文字符(比如中文、日文等),由于它们的 Unicode 编码需要多个字节来表示,因此在某些情况下会被认为占据了多个字符长度。
对于表情符号(emoji)或者一些特殊符号,它们的 Unicode 编码可能会采用代理对(surrogate pair)的形式来表示,这种形式将每个字符拆分为两个 16 位的编码单元,因此在某些计算中,每个代理对被视为占据了两个字符长度。所以在这种情况下,为了准确计算字符数,需要将表情符号或者特殊符号看做占据了两个字符的长度。
在实际开发中,开发者根据需求来决定如何处理这些特殊字符的字符长度计算规则,有时候会采用每个特殊符号占据两个字符的计算方式,以确保字符长度的准确性。而有些情况下,开发者可能会希望每个特殊字符只占一个字符长度(比如用户输入限制),这需要根据具体业务需求来定义相应的处理方法。
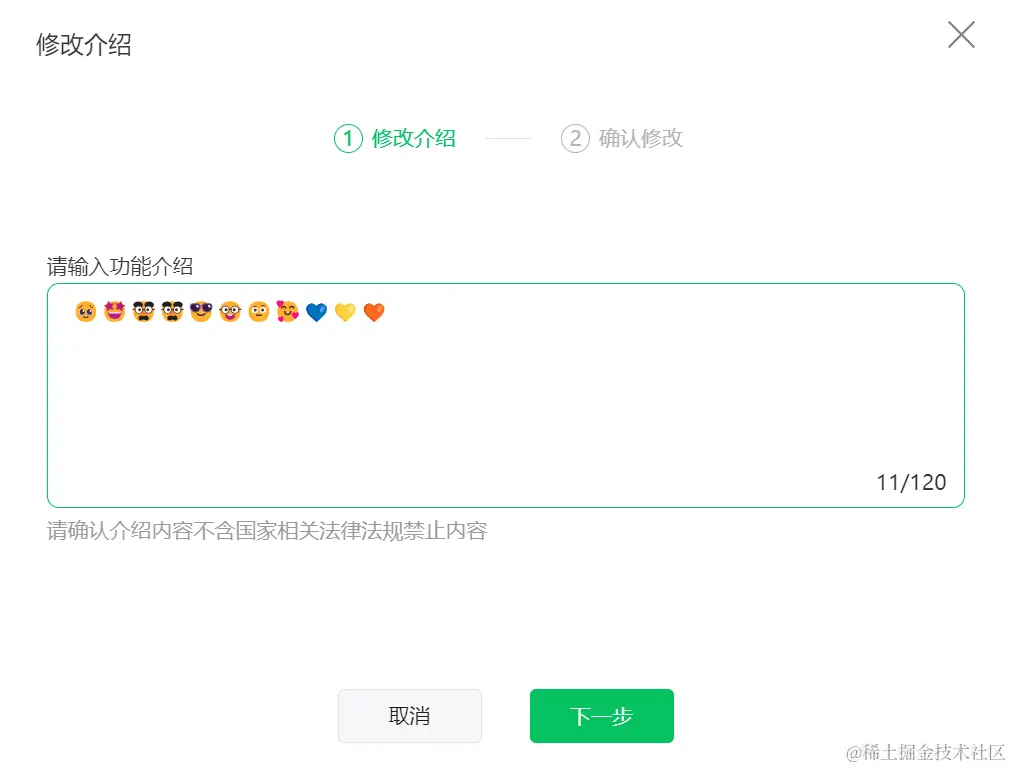
按照用户输入的内容去计算字符数,原有是emoji表情跟中文都是占2字符的,现以1字符做处理。
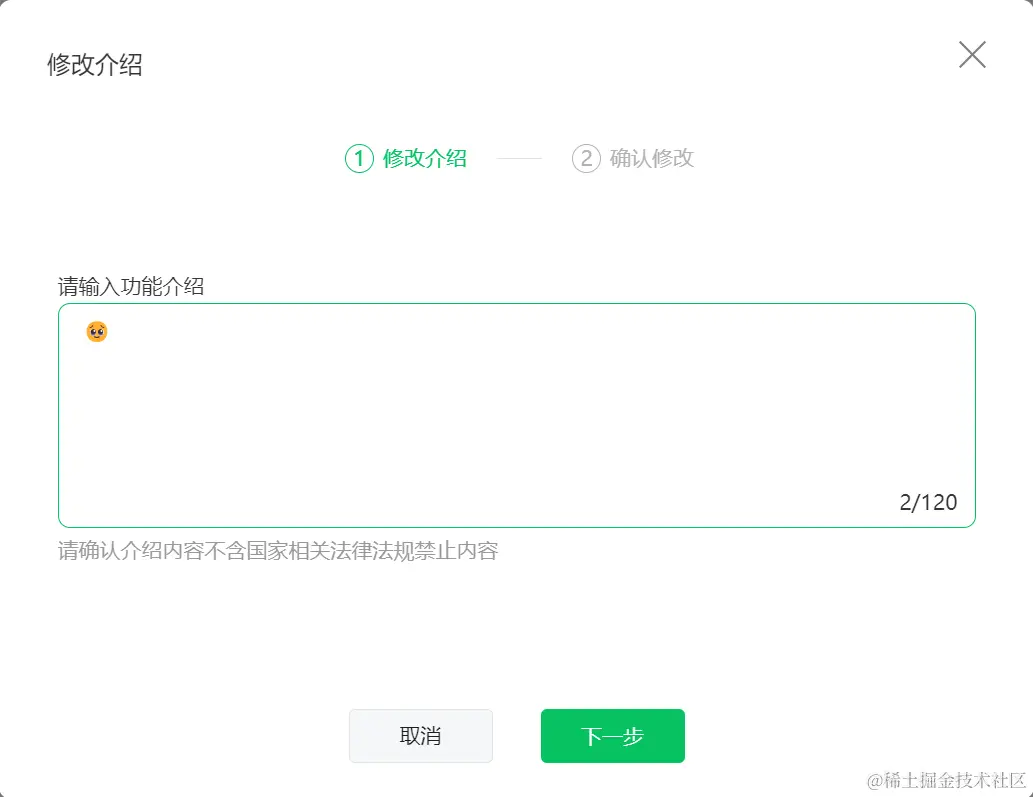

写一个包含表单内容的 HTML 结构,主要功能是要求用户输入功能介绍,并限制介绍内容的长度不超过 120 个字。
{{getLen(value)}}/120● 功能介绍长度不超过120个字
请确认介绍内容不含国家相关法律法规禁止内容
这里获取当前内容是调用了getLen的方法:
定义了一个对象 methods,其中包含了一个函数 getLen(v)。这个函数的作用是获取字符串 v 的长度,考虑到了表情字符的情况。
具体来说,函数内部使用正则表达式 /[uD800-uDBFF][uDC00-uDFFF]|./g; 匹配字符串 v 中的 Unicode 字符,其中包括标准的字符以及代理对。然后使用 match 方法将匹配到的字符存储在数组 surrogatePairs 中,或者若没有匹配结果则赋值为空数组 []。
最后,函数返回数组 surrogatePairs 的长度,即字符的实际数量,来计算字符串 v 的实际长度(包括表情字符)。
methods: {
// 获取字符长度
getLen(v) {
const regex = /[uD800-uDBFF][uDC00-uDFFF]|./g;
const surrogatePairs = v.match(regex) || [];
const actualLength = surrogatePairs.length; // 计算表情字符的实际长度
return actualLength; // 按照长度计算
},
}

到此这篇关于vue处理emoji表情占位符的操作方法的文章就介绍到这了,更多相关vue处理表情占位符内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

