
前言
故事要从我们公司的新官网说起,新官网是叫外包做的,前后端没有分离,对,你没听错,都到了 2023 年的今天,新项目依然是前后端混在一起,堆成一座屎山,然后通过模板渲染展示网页。
当然,对于非研发的,技术栈咋样都不重要,又不是不能用~
各位看官,听到上面的情况,是不是隐隐约约感觉到会有啥惊喜(惊吓)
哈,你来翻译翻译,什么叫惊喜?好,那我来翻译翻译,惊喜(bushi)就是自从新官网上线后,PV(页面访问量)下降了 50%。是的,你没看错,原因就是打开官网巨卡,一般需要 7~8s。
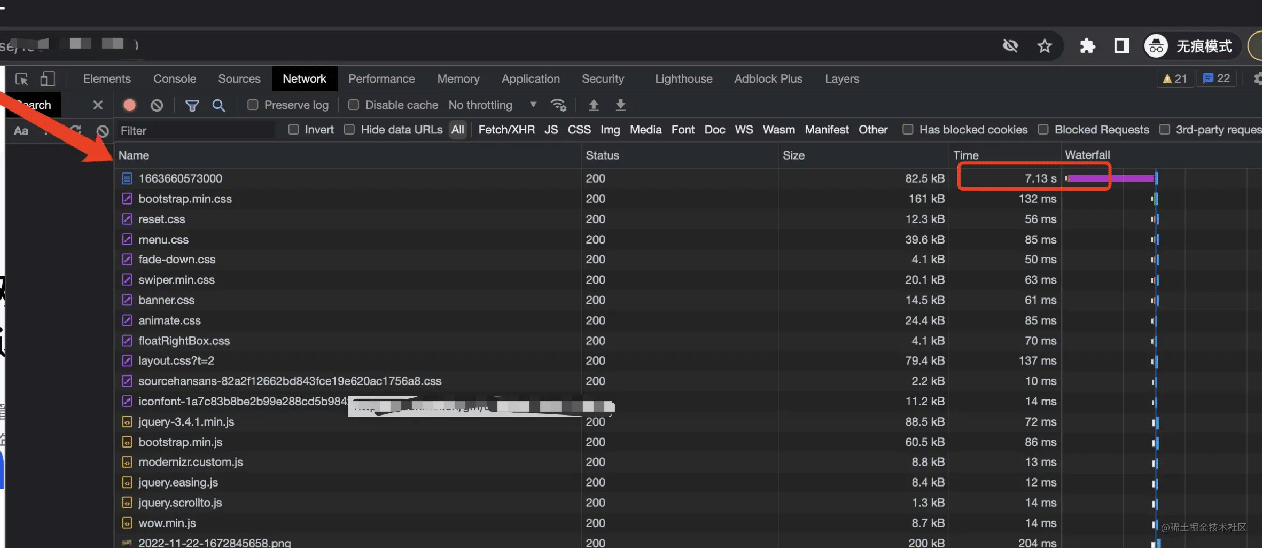
就单单请求个 html,就需要耗费 7s+的时间。
运营那边被老板亲切问候后,就跑过来找我们研发帮忙看问题,把情况说的特严重,唉,最终还不是得我们帮忙处理烂摊子
那没办法,我们就开始分析一通,啪的一下,很快呀,就找到了加载贼慢的原因:
- 刚才所说的服务端响应慢,那这个交给后端去搞就好(这个是重中之重)
- 官网的图片请求是在是太多了,而我们知道 http 请求是有次数限制的(http1.1),太多的话其他只能处于阻塞状态
那第二点自然是需要前端去搞了,图片太多,导致 http 请求太多,那好办,把小图片转 base64 不就好。 嗯,思路很简单,如果是前后端分离的项目,我们一般无脑配置 webpack url-loader 的体积限制就好,或者配置 webpack5 的 asset,即在导出一个 data URI 和发送一个单独的文件之间自动选择:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | rules: [ { test: /.(png|jpe?g|svg|gif)$/, //webpack4 start use: [ { loader: 'url-loader', options: { limit: 10 * 1024 }, }, ], //webpack4 end // webapack5 start type:'asset/inline', parser: { dataUrlCondition: { maxSize: 10 * 1024, // 小于10k则转为base64 }, }, // webapack5 end }, ], |
很简单对吧,但当你想快速 cv 以上配置的时候,发现,前端代码都是混在后端代码里面,一堆 html 文件,html 里面又混杂着一堆的 Thymeleaf 语法(Thymeleaf 是一个跟 Velocity、FreeMarker 类似的模板引擎,它可以完全替代 JSP,JSP??都啥年代了)
越看越不对劲,正所谓理想很丰满,现实很骨感,唉,只能长叹一声。
但没办法,领导可不管用啥方式,只要有个方法把 html 里面图片小于某个指定值,如 10k,那就转 base64,让这些小图片不走 http 请求。
思路
那么,正常的路走不通(当然也有可能有其他更快捷的方式,只是比较赶,暂时想不到更好、更简单的方式实现),那就另辟蹊径。
全体流程如下:
1. mvn clean // marven 清空输出目录
2. mvn compile // marven编译
3. 将所有 html 的的小图片都转 base64
4. mvn package // marven 打包
以上主要重点关注第3点,既然要将所有 html 的的小图片都转 base64,那么自然而然可以通过写个 node 脚本来实现,大概可以分为以下几个步骤:
- 递归读取指定目录下的所有 html 文件路径 htmlPaths,这里我们假设所有 html 都放在 backend/templates 里面
- 遍历每个路径,读取对应的 html,然后通过正则匹配到每个 html 里面的所有 img 对应的 src,存放到 imgSrcs 里面
- 遍历每个 img 的 src,读取 imageBuffer,并转为 base64
- 再将得到的 base64 替换原先的 src
- 最后将新的 html 替换旧的 html
上面的步骤应该比较清晰的,不过,等一下,最近 chatgpt 不是很火吗,让它来写不就好~
实现过程
递归读取指定目录下的所有 html 文件路径 htmlPaths
首先判断入口目录的下的内容,是文件的话就判断是否以.html 结尾,是的话则放入 htmlFilePaths,是目录的话则递归遍历,那我们来问神奇的 chatgpt:
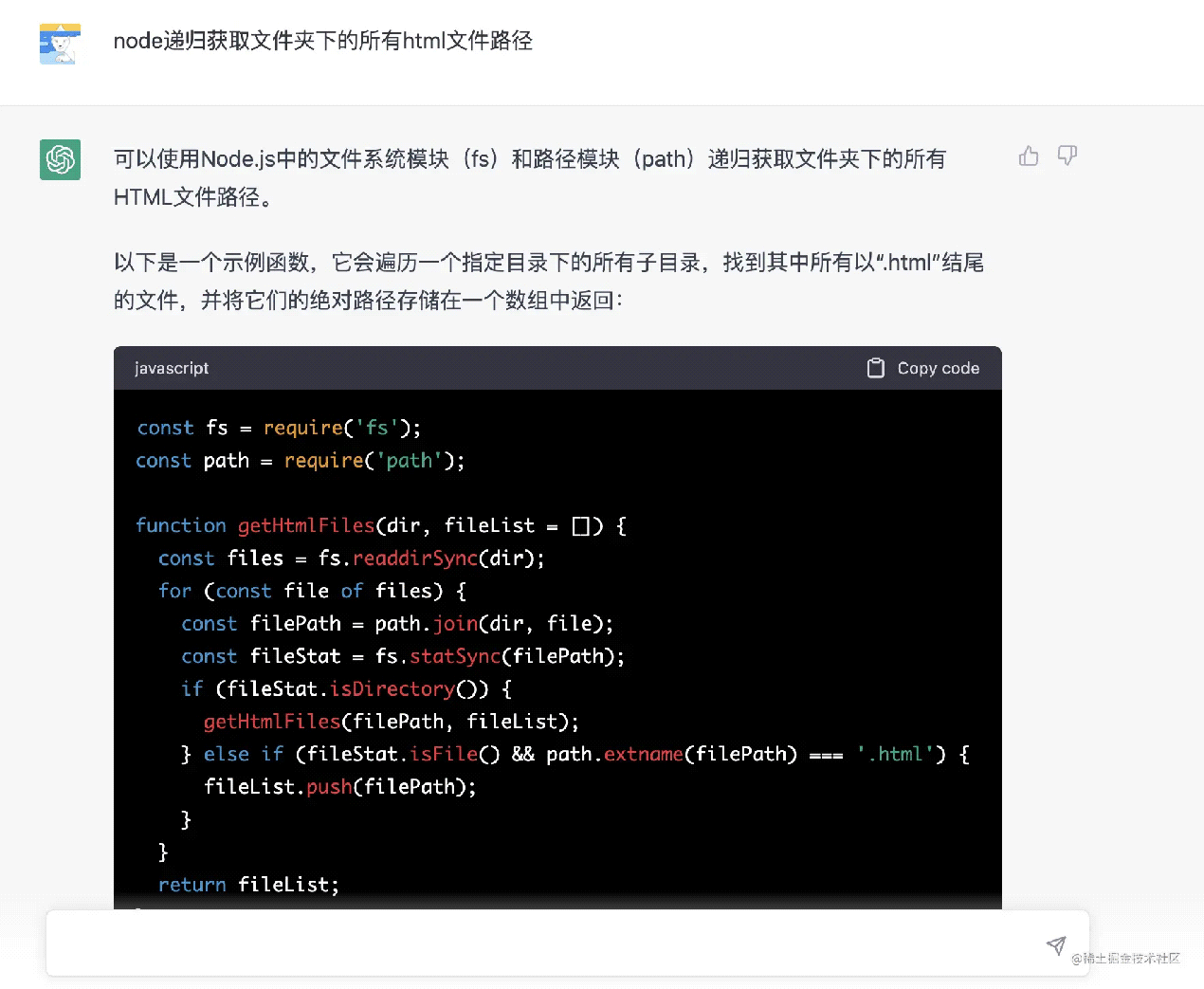
嗯,很不错,第一次几乎完美,顺利拿到所有的 html 路径
获取每个 html 里面的图片 src
自然而然想到用正则匹配来做,所以我马上问:
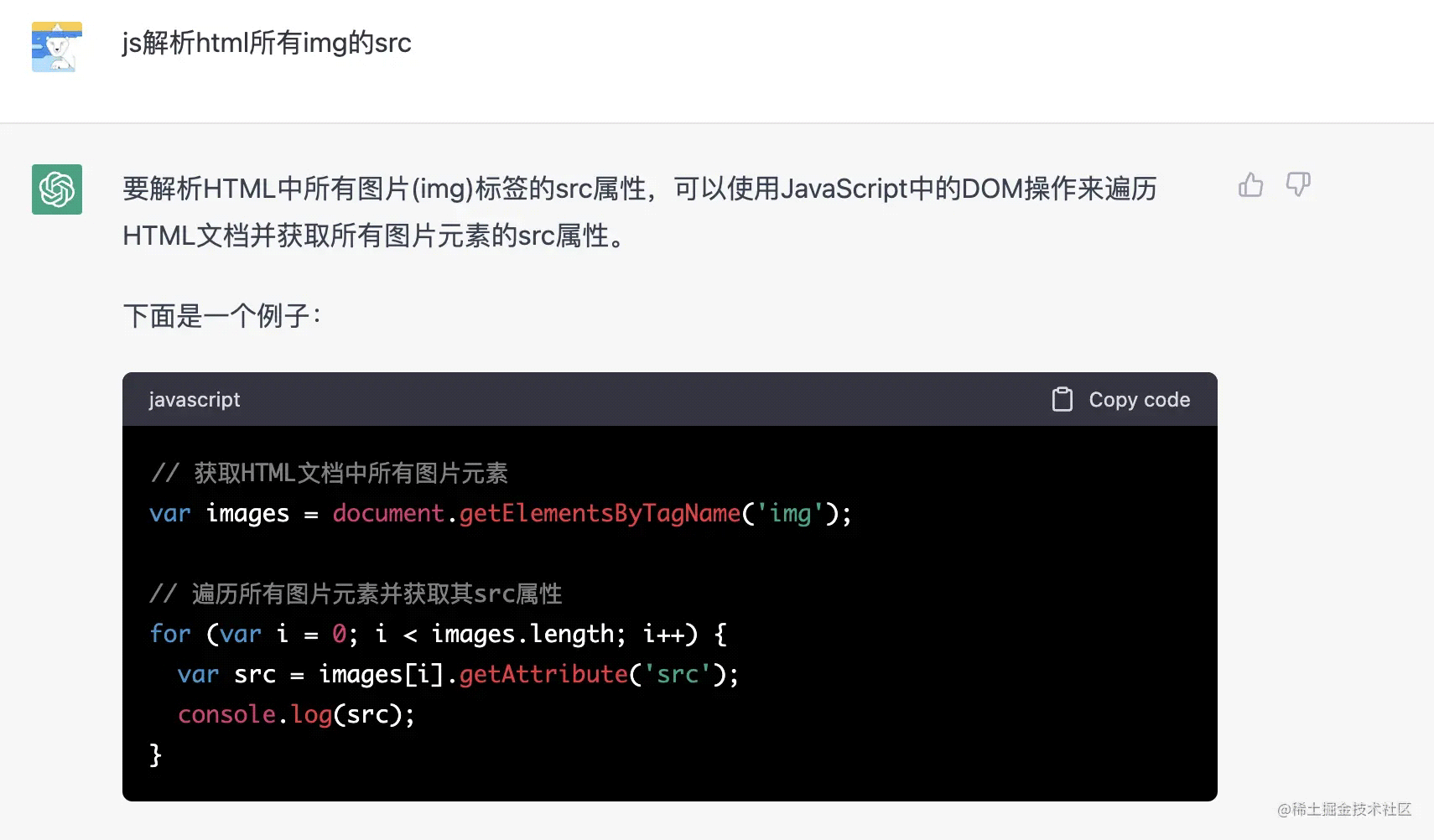
一看结果就不是我想要的,当然也是我描述的不清晰,导致 chatgpt 以为要获取 html 文档的图片 src
获取 html 字符串的所有图片 src
应该问要获取 html 字符串的,所以我接着问:
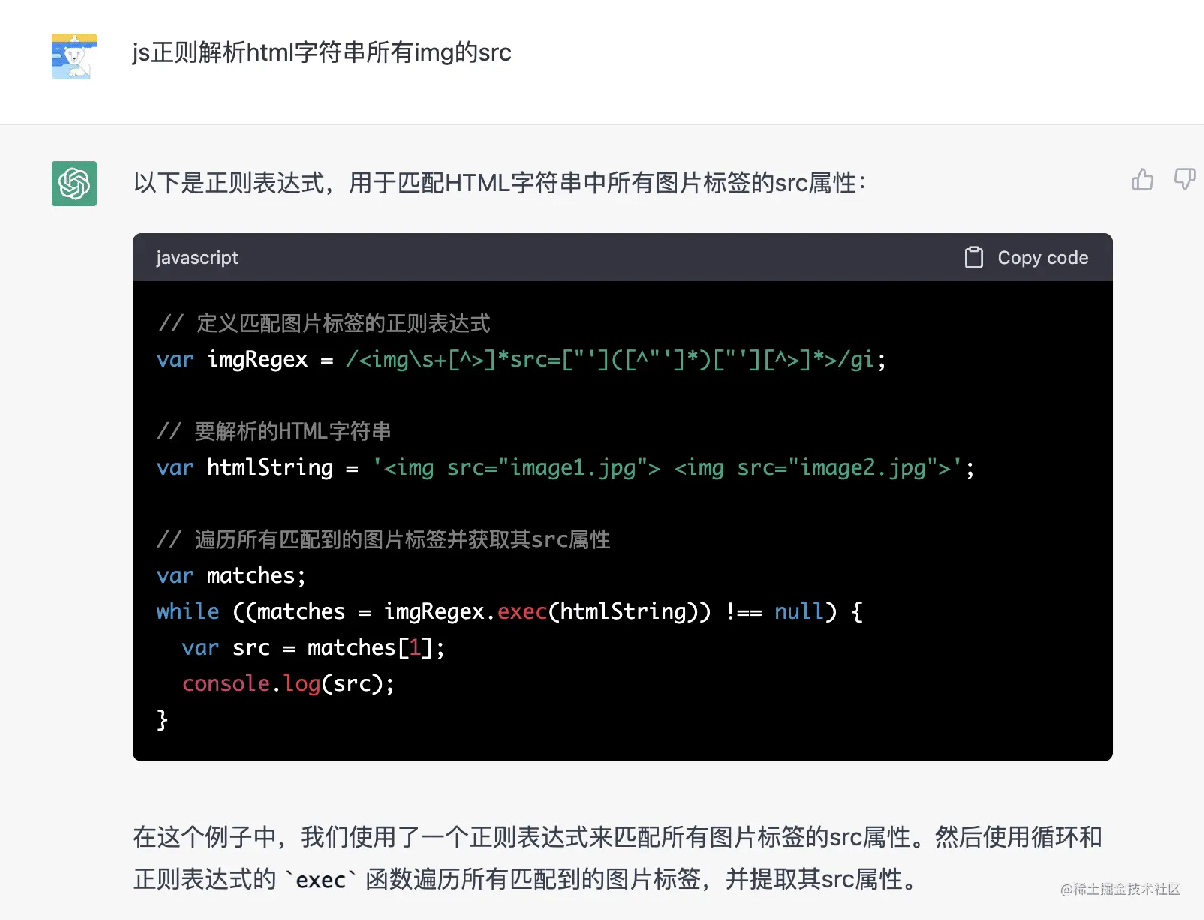
1 2 3 4 5 6 7 8 9 10 | // 定义匹配图片标签的正则表达式var imgRegex = /<img>]*src=["']([^"']*)["'][^>]*>/gi;// 要解析的HTML字符串var htmlString = '<img decoding="async" src="image1.jpg"><img decoding="async" src="image2.jpg">';// 遍历所有匹配到的图片标签并获取其src属性var matches;while ((matches = imgRegex.exec(htmlString)) !== null) { var src = matches[1]; console.log(src);} |
运行后,得到的结果:

不错不错,再接再厉。
忽略注释的代码
但 html 代码可能 img 被注释了,如 ,那么我们实际上没必要去转换,故我们让个让其忽略注释的:

那我们来试试,将其中注释代码中插入 img,看看是否会解析:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | // 定义匹配图片标签的正则表达式var imgRegex = /<img>]*src=["']([^"']*)["'][^>]*>/gi;// 定义匹配注释的正则表达式var commentRegex = /<!--[sS]*?-->/g;// 要解析的HTML字符串var htmlString = ' <img decoding="async" src="image1.jpg"><img decoding="async" src="image2.jpg">';// 删除所有注释htmlString = htmlString.replace(commentRegex, '');// 遍历所有匹配到的图片标签并获取其src属性var matches;while ((matches = imgRegex.exec(htmlString)) !== null) { var src = matches[1]; console.log(src);} |
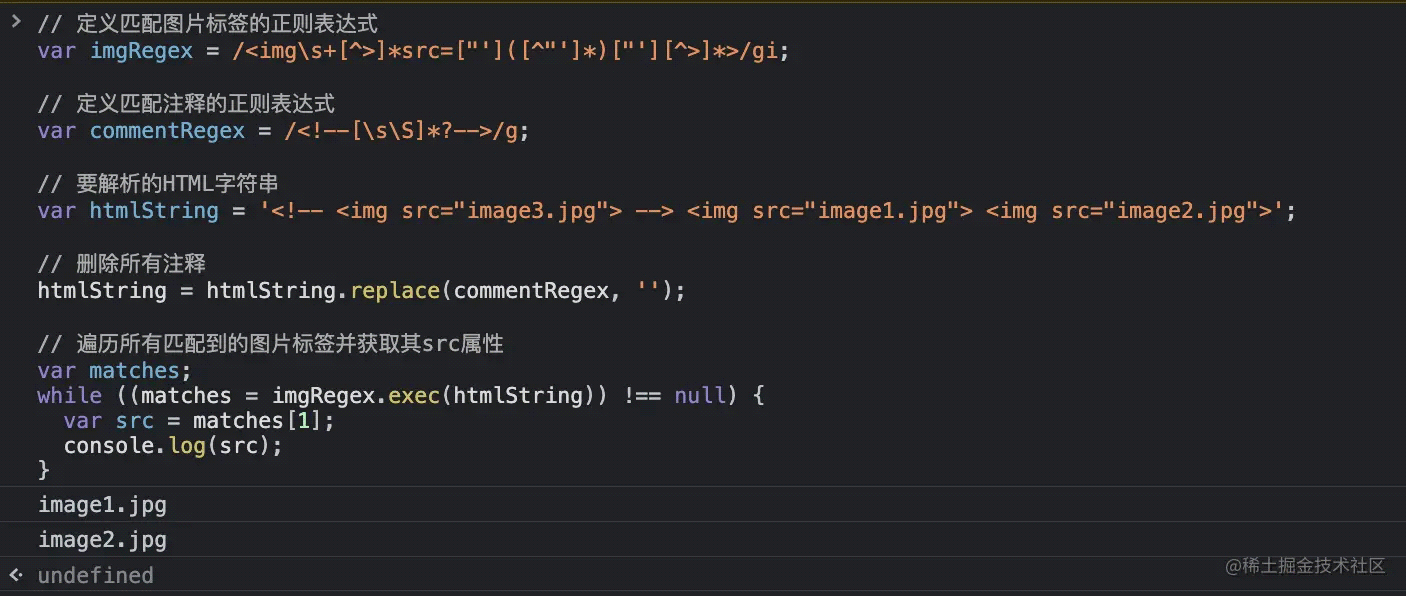
可以看到被注释掉的 image3 不会被匹配到
本身是 base64,则忽略
继续继续,但图片 src 可能一开始就是 base64 了,就没必要转了,而 base64 是 data:image 开头的,所以我们再让它加下条件:

1 2 3 4 5 6 7 8 9 10 | // 定义匹配图片标签的正则表达式var imgRegex = /<img>]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi;// 要解析的HTML字符串var htmlString = '<img decoding="async" src="image1.jpg"><img decoding="async" src="image/png;base64,iVBORw0KG..."><img decoding="async" src="image2.jpg">';// 遍历所有匹配到的不以 data:image 开头的图片标签并获取其src属性var matches;while ((matches = imgRegex.exec(htmlString)) !== null) { var src = matches[1]; console.log(src);} |
我们运行看下结果
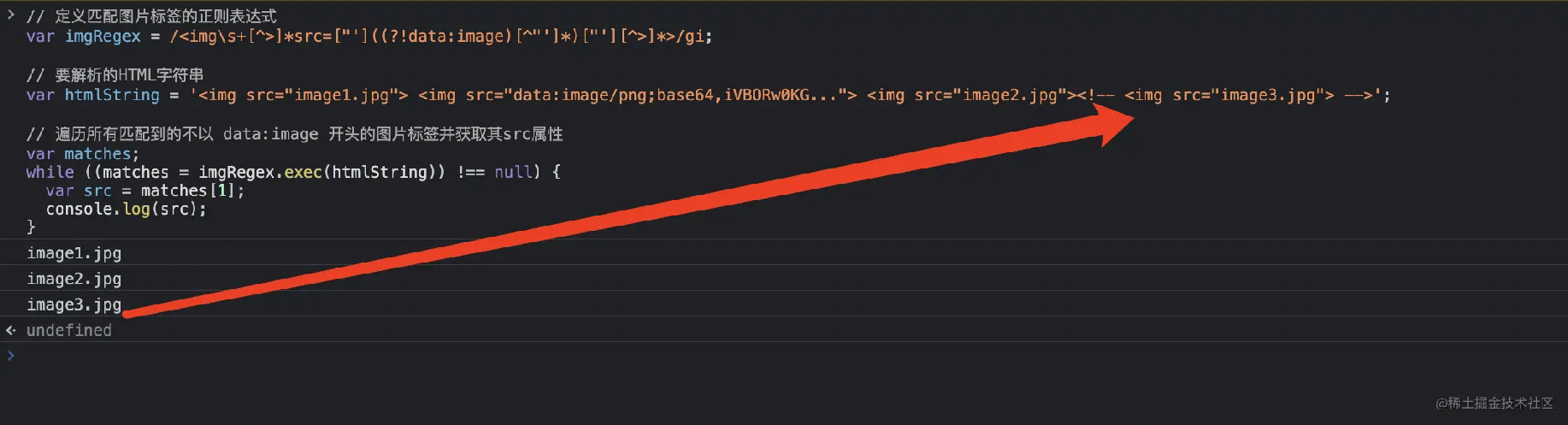
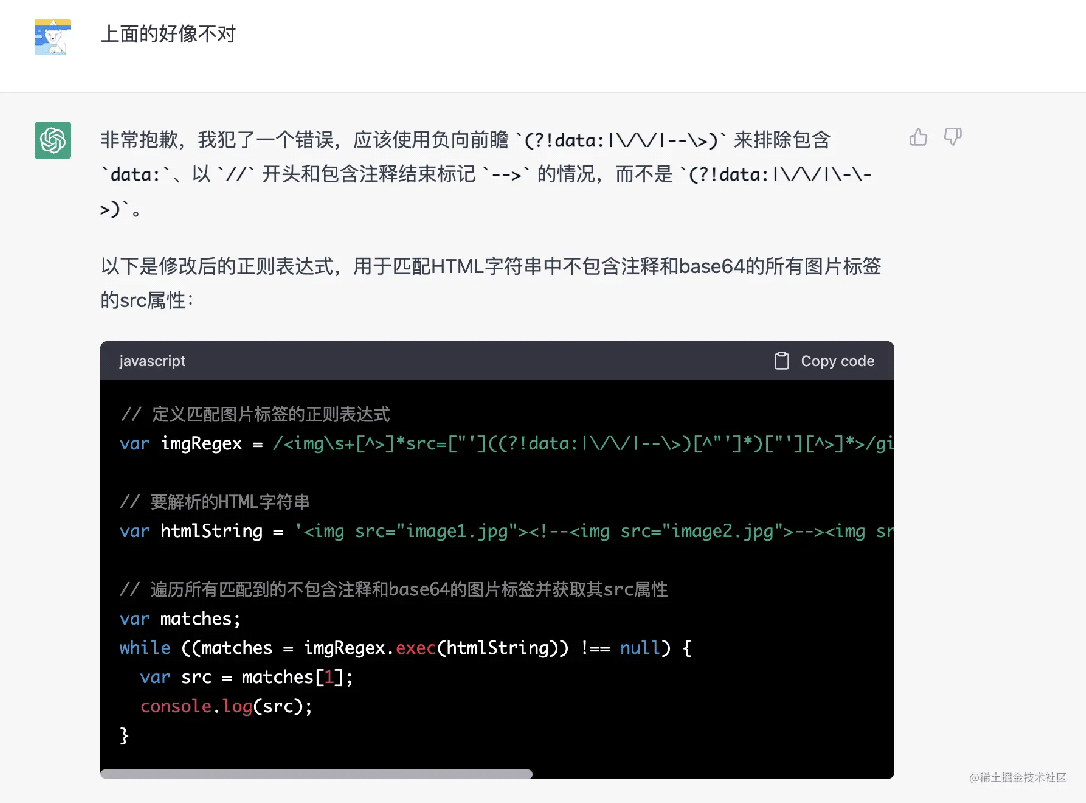
成功跳过了 base64 的,但是,好像没有了忽略注释代码的条件,啊这。。
所以我就让他忽略注释和 base64 的,但好像一直丢三落四,按下葫芦浮起瓢,大家可以看看
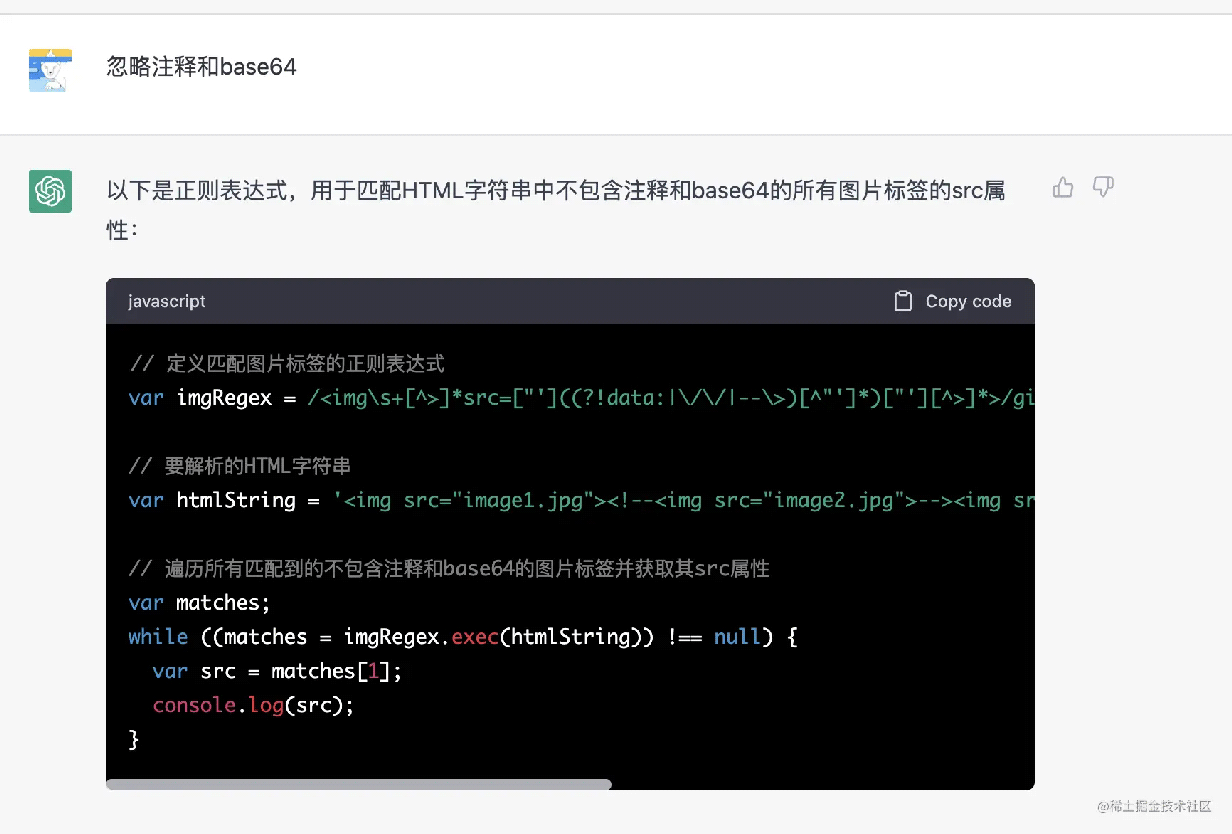
上面的注释的被匹配到了
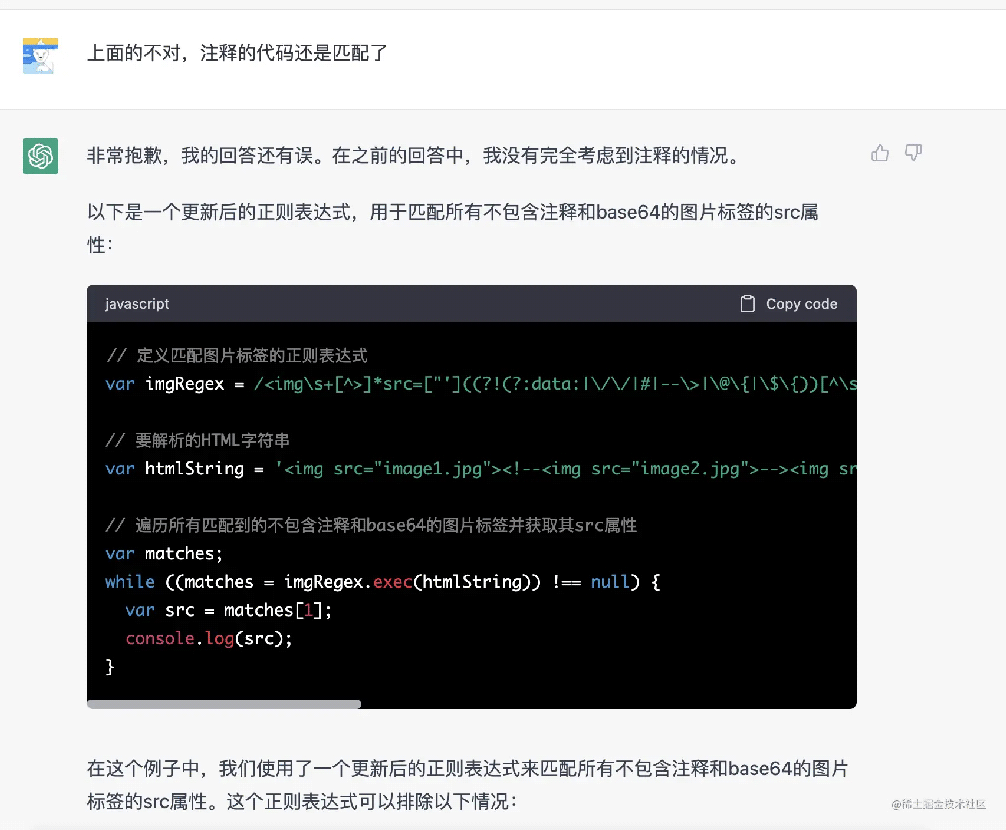
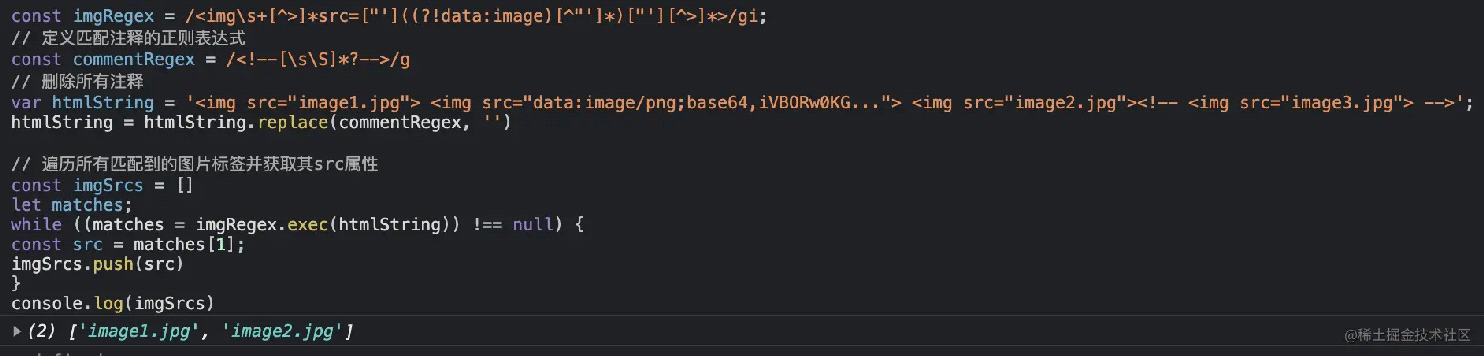
注释又又又被匹配到了,算了,我直接问如果忽略 base64,然后再组合忽略注释的就好,组合后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | const imgRegex = /<img>]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi;// 定义匹配注释的正则表达式const commentRegex = /<!--[sS]*?-->/g// 删除所有注释var htmlString = '<img decoding="async" src="image1.jpg"><img decoding="async" src="image/png;base64,iVBORw0KG..."><img decoding="async" src="image2.jpg">';htmlString = htmlString.replace(commentRegex, '')// 遍历所有匹配到的图片标签并获取其src属性const imgSrcs = []let matches;while ((matches = imgRegex.exec(htmlString)) !== null) {const src = matches[1];imgSrcs.push(src)}console.log(imgSrcs) |
忽略 Thymeleaf 语法
还有个问题,img 的 src 可能是通过服务端渲染导入的,那么我们要忽略掉,大致语法为
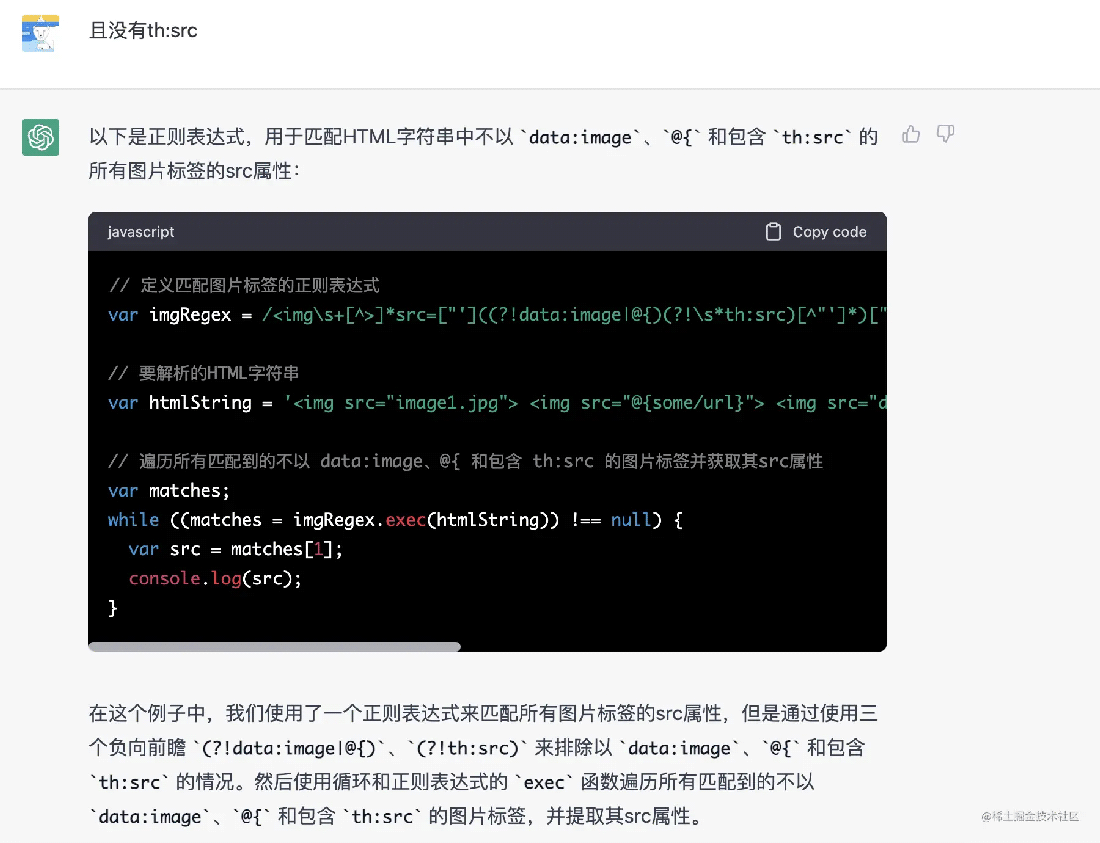
1 2 3 4 5 6 7 8 9 10 | // 定义匹配图片标签的正则表达式var imgRegex = /<img>]*src=["']((?!data:image|@{)(?!s*th:src)[^"']*)["'][^>]*>/gi;// 要解析的HTML字符串var htmlString = '<img decoding="async" src="image1.jpg"><img decoding="async" src="@%7Bsome/url%7D"><img decoding="async" src="image/png;base64,iVBORw0KG..."><img decoding="async" src="image2.jpg">';// 遍历所有匹配到的不以 data:image、@{ 和包含 th:src 的图片标签并获取其src属性var matches;while ((matches = imgRegex.exec(htmlString)) !== null) { var src = matches[1]; console.log(src);} |

上面的@{可以忽略,实际上也是属于 Thymeleaf 语法,屏蔽 th:src 即可
结合起来,封装成一个函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | function getImgSrcInHtml(htmlString) { /** 定义匹配图片标签的正则表达式 * 1.src中不以data:image开头,即不以base64开头,没必要再转化了 * 2.不是th:src * 3.忽略注释的代码 * */ const imgRegex = /<img>th:]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi; // 定义匹配注释的正则表达式 const commentRegex = /<!--[sS]*?-->/g // 删除所有注释 htmlString = htmlString.replace(commentRegex, '') // 遍历所有匹配到的图片标签并获取其src属性 const imgSrcs = [] let matches; while ((matches = imgRegex.exec(htmlString)) !== null) { const src = matches[1]; imgSrcs.push(src) } return imgSrcs.filter(Boolean)} |
运行下,看下结果:
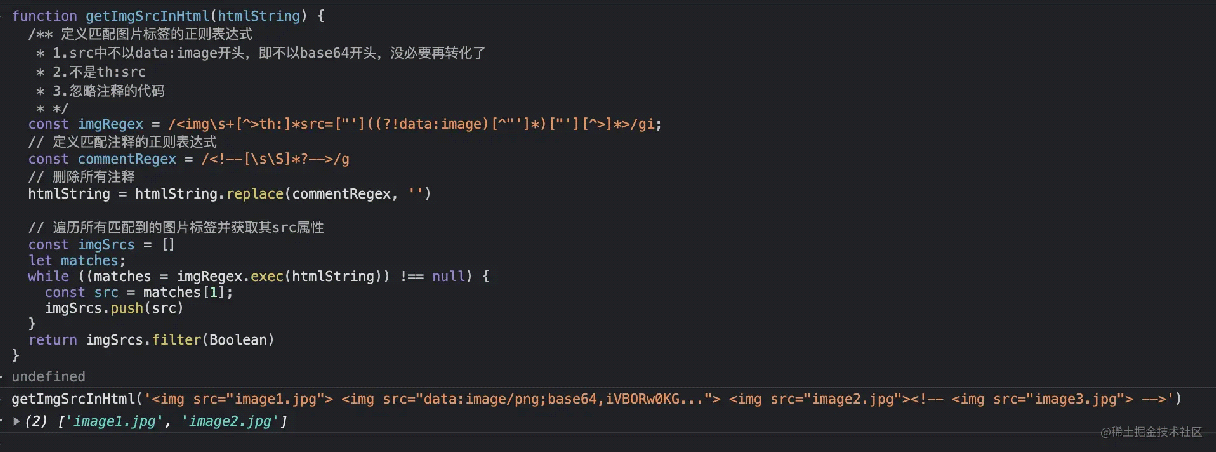
src 转 base64
自此,我们拿到所有 html 里面的 src 了,那么判断下是否小于指定 size,是的话转 base64
获取文件大小可通过 fs 的 statSync 来拿到对应文件的 size,如下
1 2 3 4 5 | /** 获取文件大小 */function getFileSize(filePath) { const stat = fs.statSync(filePath) return stat.size} |
如果满足条件则将图片转 base64,而图片本身是 Buffer,所以要转一下:
1 2 3 4 5 6 7 8 9 | /** 图片转成base64 */function imageToBase64(filePath) { // 读取图片文件 const imageBuffer = fs.readFileSync(filePath) const extname = getExtname(filePath) // 将图片文件转换为 base64 编码字符串 const base64String = Buffer.from(imageBuffer).toString('base64') return `data:image/${extname.slice(1)};base64,${base64String}`} |
通过加上前缀data:image/${extname.slice(1)};base64,,其中 extname 是文件后缀名,通过path.extname拿到:
1 2 3 4 | /** 获取后缀名 */function getExtname(filePath) { return path.extname(filePath)} |
每得到一个 base64,则替换原先的 src:
1 | htmlString = htmlString.replace(src, imgBase64) |
最后将新的 html 替换旧的 html
html 下满足条件的 src 全部替换好后,就可以将新的 html 替换老的了,实际上也就是重写回去:
1 | writeFile(htmlPath, htmlString) |
性能优化
但我们发现整个过程中有两处可以优化代码:
- 如果 src 大于指定尺寸,那么下次遇到直接跳过,不再获取尺寸大小
- 一个图片可能被多处引用到,那么转 base64 后,下次遇到就没必要再转了,直接复用即可
针对第一点,我们可以通过声明一个 Set,存放大于指定尺寸的 src:
1 2 3 4 5 6 7 8 9 10 11 12 | for (const src of imgSrcs) { /** 之前已经大于了,这次遇到就直接跳过即可 */ if (imgOverSizeSet.has(src)) continue let absoluteSrc = src // 如果不是相对路径,那么转换为绝对路径 if (!src.startsWith('.')) absoluteSrc = path.join(STATIC_PATH, src) // 不存在或者超出限制,则不替换 if (getFileSize(absoluteSrc) >= FILE_LIMIE_SIZE) { imgNotExistOrOverSizeSet.add(src) continue }} |
针对第二点,我们可以通过声明一个 Map,key 为 src,value 为 base64:
1 2 | /** 存imgSrc -> 图片base64 */const imgSrc2Base64Map = new Map() |
每次判断到对应的 src 有值,则直接拿之前的 base64,不再转化:
1 2 3 4 5 | let imgBase64 = imgSrc2Base64Map.get(src)if (!imgBase64) { imgBase64 = imageToBase64(absoluteSrc) imgSrc2Base64Map.set(src, imgBase64)} |
总的代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 | const fs = require('fs')const path = require('path')function resolve(relativePath) { return path.resolve(__dirname, relativePath)}/** 静态资源路径 */const STATIC_PATH = resolve('xxx')/** html模板路径 */const TEMPLATE_PATH = resolve('yyy')/** 文件大小限制 10K */const FILE_LIMIE_SIZE = 1024 * 10/** 图片转成base64 */function imageToBase64(filePath) { // 读取图片文件 const imageBuffer = fs.readFileSync(filePath) const extname = getExtname(filePath) // 将图片文件转换为 base64 编码字符串 const base64String = Buffer.from(imageBuffer).toString('base64') return `data:image/${extname.slice(1)};base64,${base64String}`}/** 获取文件大小 */function getFileSize(filePath) { const stat = fs.statSync(filePath) return stat.size}/** 获取后缀名 */function getExtname(filePath) { return path.extname(filePath)}/** 获取所有html路径 */function getHtmlPaths(dir, filePaths = []) { const files = fs.readdirSync(dir); for (const file of files) { const filePath = path.join(dir, file); const fileStat = fs.statSync(filePath); if (fileStat.isDirectory()) { getHtmlPaths(filePath, filePaths); } else if (fileStat.isFile() && getExtname(filePath) === '.html') { filePaths.push(filePath); } } return filePaths;}function readFile(filePath) { return fs.readFileSync(filePath, 'utf-8')}function writeFile(filePath, source) { return fs.writeFileSync(filePath, source)}/** 获取html中满足规则的img src */function getImgSrcInHtml(htmlString) { /** 定义匹配图片标签的正则表达式 * 1.src中不以data:image开头,即不以base64开头,没必要再转化了 * 2.不是th:src * 3.忽略注释的代码 * */ const imgRegex = /<img>th:]*src=["']((?!data:image)[^"']*)["'][^>]*>/gi; // 定义匹配注释的正则表达式 const commentRegex = /<!--[sS]*?-->/g // 删除所有注释 htmlString = htmlString.replace(commentRegex, '') // 遍历所有匹配到的图片标签并获取其src属性 const imgSrcs = [] let matches; while ((matches = imgRegex.exec(htmlString)) !== null) { const src = matches[1]; imgSrcs.push(src) } return imgSrcs.filter(Boolean)}/** 主程序 */function main() { const htmlPaths = getHtmlPaths(TEMPLATE_PATH) /** 存imgSrc -> 图片base64 */ const imgSrc2Base64Map = new Map() /** 存不存在,或者超过指定大小的img */ const imgNotExistOrOverSizeSet = new Set() htmlPaths.forEach(htmlPath => { let htmlString = readFile(htmlPath) const imgSrcs = getImgSrcInHtml(htmlString) if (!imgSrcs.length) return for (const src of imgSrcs) { if (imgNotExistOrOverSizeSet.has(src)) continue let absoluteSrc = src // console.log(imgSrcs) // 如果不是相对路径,那么转换为绝对路径 if (!src.startsWith('.')) absoluteSrc = path.join(STATIC_PATH, src) const isExist = fs.existsSync(absoluteSrc) if (!isExist) console.log('not isExist', src) // 不存在或者超出限制,则不替换 if (!isExist || getFileSize(absoluteSrc) >= FILE_LIMIE_SIZE) { imgNotExistOrOverSizeSet.add(src) continue } let imgBase64 = imgSrc2Base64Map.get(src) if (!imgBase64) { imgBase64 = imageToBase64(absoluteSrc) imgSrc2Base64Map.set(src, imgBase64) } htmlString = htmlString.replace(src, imgBase64) } // 替换好后,写回 writeFile(htmlPath, htmlString) })}main() |
总结
因为太多的小图片导致 http 请求阻塞,所以要把满足条件的小图片转为 base64, 而前端的 html 混在在后端代码里面,且里面混杂着 Thymeleaf 模板语法,想通过 webpack 打包的方式看起来好像不行(至少目前不知道咋办),所以退而求其之自己写个脚本来处理。
大致思路就是:
- 读取所有 html,匹配到里面的所有 img 的 src
- 匹配的过程中我们要忽略注释的代码、已经是 base64 的图片、Thymeleaf 模板语法的,涉及到挺多的正则语法,这部分我通过调戏 chatgpt 来实现,虽然过程中不是十分完美
- src 可能被重复用到,所以这里又可以优化为:
- 如果 src 大于指定尺寸,那么下次遇到直接跳过,不再获取尺寸大小
- 一个图片可能被多处引用到,那么转 base64 后,下次遇到就没必要再转了,直接复用即可
以上就是让chatgpt将html中的图片转为base64方法示例的详细内容,更多关于chatgpt html图片转base64的资料请关注IT俱乐部其它相关文章!

