
当我们使用命令行批量从 S3 上拷贝文件或统计文件数量时,希望能排除掉 S3 上以 _$folder$ 结尾的占位文件,这个正则表达式应该怎么写呢?
Shell 实现
以下是统计 S3 某个位置下的除 _$folder$ 结尾的文件的文件数量:
1 | aws s3 ls --recursive s3://my-s3-location/ | grep -v '.*_$folder$' | wc -l |
使用 grep 过滤是比较简单的,因为 grep 有一个 -v,--invert-match 参数:“反向匹配”,即:过滤掉match 上的行。
Java 实现
相较而言,如果是 java 程序,这个正则就很有些难写了,应为 java 正则接口并没有“反向匹配”这种设置,这个 正则要这样写:^(?!.*[_]$folder$$).*$,我们以 s3-dist-cp 这个命令为例,它的 --srcPattern 参数就是一个 Java 的正则表达式,用于匹配需要拷贝的文件,如果我们要在拷贝时排除掉 S3 上那些恼人的 _$folder$ 结尾的文件,应该这样写:
1 2 3 4 5 6 7 | nohup s3-dist-cp -Dmapreduce.job.reduces=599 --src=s3://my-hbase-snapshots/usertable-20231205 --dest=hdfs://${SINK_CLUSTER_NAMENODES}:8020/user/hbase/ --srcPattern='^(?!.*[_]$folder$$).*$' --multipartUploadChunkSize=1024 &> s3-dist-cp.out &tail -f s3-dist-cp.out |
补充:
正则表达式文本过滤
grep文本过滤
1.grep 默认是按照以行为基本单位进行匹配和显示的。
2.grep默认匹配只要包含模式字符即可
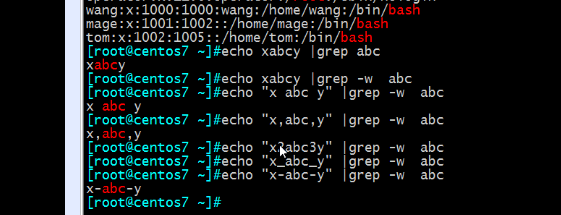
grep -w 是按单词匹配,和普通的匹配不一致
单词的分隔符, 数字加字母加下划线都算做单词的一部分
grep -f p.txt /etc/passwd
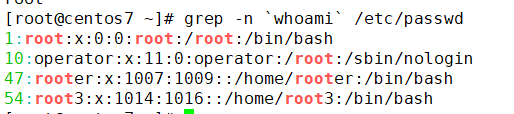
匹配显示结果的行号

grep 并且关系和 或者关系
1.并且 grep root /etc/passwd | grep shutdown
2.或者 grep -e root -e shutdown /etc/passwd
正则表达式
1.字符匹配
. 表示一个任意字符 .放在[]里面就表示.本身这个字符
2.匹配次数
某一个字符出现的次数
* 表示*号前面的字符出现的次数是不确定的
3.位置锚定
行首 ^ 不能匹配中间某段字符串的开始
行尾 $ 不能匹配中间某一段字符串的结尾
单词词首
单词词尾 root> root处于单词的最右侧
4.分组
1. echo wangwangwangggww | grep “(wang){3}”
2.后向引用
正则表达式和通配符的区别
正则表达式匹配的是文件的内容或者标准输出的字符串,通配符匹配的是文件的名称.两者操作的对象不一致.
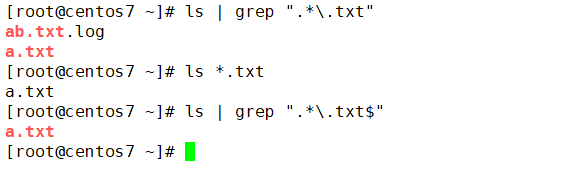
匹配字符串问题
shell执行命令的时候,正则表达式是以整个输出作为字符串内容,包括看不到的空格符号。
有些命令结果会输出一个或者多个空格,有些命令不会输出空格.



1.在表达式中()符号前面和{}括号前面都必须要加上() 和 {}.
grep “^(.*):.*1$” /etc/passwd
2.正则表达式默认从字符串的最前面开始查找,但是如果锚定的是行尾,那么正则会从尾部开始查找
1.从尾部开始查找

2.从头部开始查找

3.分组实例
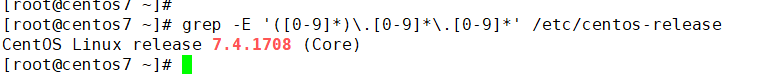

第一分组匹配到的字符串是7,最后面的[0-9]*1 表示匹配到以7结尾而且7前面可以包含任意个数字的数字
基本正则和扩展正则的区别
1.基本正则语法 小括号和大括号前面需要加上符号做转义
grep -w “[0-9]{2,3}” /etc/passwd
2.扩展正则 小括号和大括号前面不要加上转义字符
grep -Ew “[0-9]{2,3}” /etc/passwd
egrep -w “[0-9]{2,3}” /etc/passwd
到此这篇关于正则表达式:过滤 S3 上以 _$folder$ 结尾的占位文件的文章就介绍到这了,更多相关正则表达式过滤占位文件内容请搜索IT俱乐部以前的文章或继续浏览下面的相关文章希望大家以后多多支持IT俱乐部!

