写在前面
记录一次生产环境sudo启动进程频繁被Kill且不报错的异常处理过程,如果遇到同样的问题只想要解决方案,直接跳到处理方案部分即可。
问题描述
这次记录一个比较特殊的问题,先说一下这次的环境情况,大数据底座使用的是Ambari管理的HDP-3.1.5.0-152,在上面部署的二开后的Dolphinscheduler调度服务,操作系统版本是Centos7(对应版本7.6.1810)。
接下来说下问题现象,运维日常巡检应该是没有去查看任务运行的情况,只是看看数据的输入输出,然后前两天客户投诉了项目,项目上也一直没查到问题,运维这个时候去看了任务执行的情况,发现存在大量任务的状态为Kill:
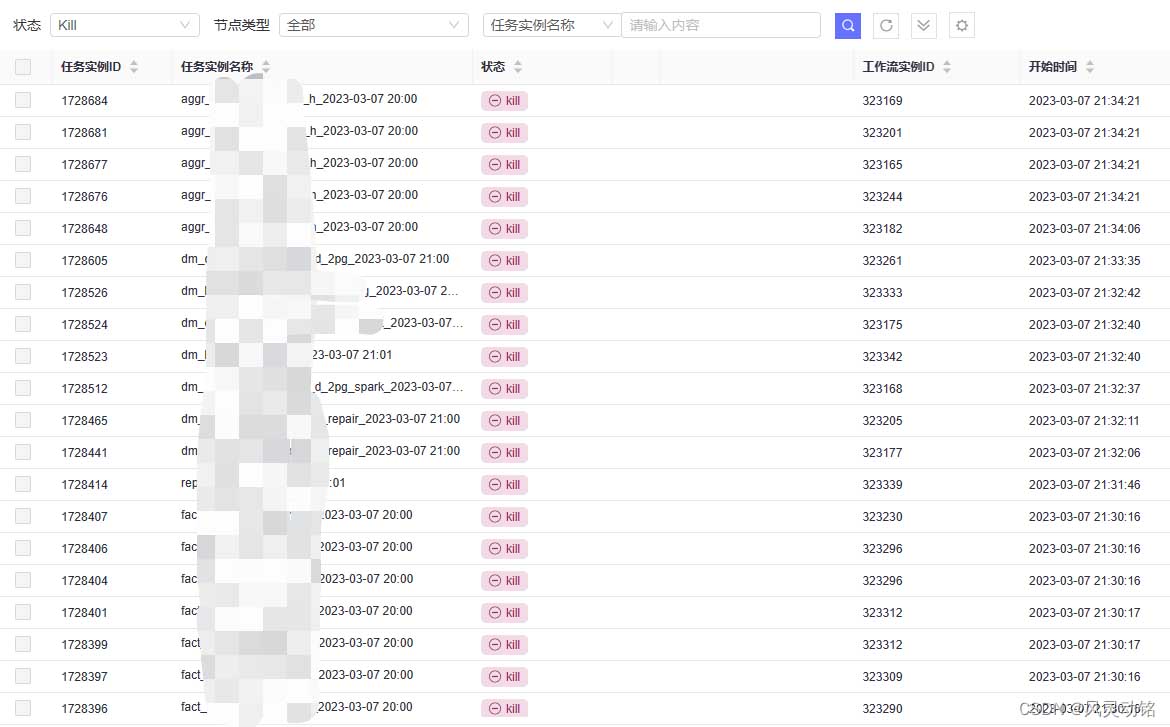
这个表现,第一印象就是是不是任务上Yarn 被.干掉了,但是同时期去查了Yarn的任务记录,并没有任何被Kill的任务:

于是就怀疑是Dolphinscheduler自己杀的任务,项目就安排调度的二开团队上来排查;查了一段时间,开发人员看到日志有大量报负载高的日志,所以认为是服务器负载过高导致的问题,关键日志如下:
[WARN] 2023-03-07 00:31:38.841 org.apache.dolphinscheduler.server.master.dispatch.host.LowerWeightHostManager:[163] – load is too high or availablePhysicalMemorySize(G) is too low, it’s availablePhysicalMemorySize(G):247.3,loadAvg:100.42
[WARN] 2023-03-07 00:31:43.842 org.apache.dolphinscheduler.server.master.dispatch.host.LowerWeightHostManager:[163] – load is too high or availablePhysicalMemorySize(G) is too low, it’s availablePhysicalMemorySize(G):247.3,loadAvg:100.42
[WARN] 2023-03-07 00:31:48.843 org.apache.dolphinscheduler.server.master.dispatch.host.LowerWeightHostManager:[163] – load is too high or availablePhysicalMemorySize(G) is too low, it’s availablePhysicalMemorySize(G):247.46,loadAvg:125.33
这确实也是怀疑方向,随后项目上的维护人员也尝试降低机器负载,减少资源占用之类的方法,不过都没改观这个问题,同事就来找我,看看我有什么头绪。
问题排查
高负载现象排查
接下来说说我的整体排查和定位过程,首先是针对开发人员推断的负载高导致的问题进行了排查,确实存在负载很高的问题,但是和Kill的发生时间无法吻合,不过既然存在这个问题也要稍微排查和处理下,经过定位,发现是客户部署的监控agent有问题,启动大量的线程并且挂死,把负载拉高了,那么先把这部分僵尸进程干掉:

随着负载降低下来,问题依旧存在:

日志排查
基本可以确认开发所说的机器负载导致的问题是站不住脚的,Worker日志中还是大量任务被Kill的记录:
[INFO] 2023-03-07 00:35:14.961 org.apache.dolphinscheduler.server.worker.runner.TaskExecuteThread:[151] – task instance id : 1707926,task final status : KILL,exitStatusCode:137
[INFO] 2023-03-07 00:35:14.961 org.apache.dolphinscheduler.server.worker.runner.TaskExecuteThread:[163] – ========任务执行完成,准备发送任务状态,退出状态码137
这里从日志出发,KILL任务的退出码是137,在这一点的认知上,很多人存在误区,这个状态码是由128+9的来的,含义就是程序接受到了一个信号,信号值为9,而9我们都知道代表的信号是SIGKILL。
退出码137很多人以为就代表内存OOM,由内核Kill,这个是误区,一个进程被内核oomkill他的退出状态码确实是137,但是其他发送SIGKILL信号的行为也会表现为退出状态码137,这个Reddit上有个老哥说过:
Article needs correcting. 137 isn’t some magic shorthand for out of memory. An exit code of 128+n means the process received signal number n and exited because of it. 137=128+9, signal 9 is SIGKILL. SIGKILL can be sent due to failing liveness probes.
OK,言归正传,这里我去和研发也核实了Dolphinscheduler的逻辑,他们确认不会是Dolphinscheduler自己发动的kill动作,那么我也就不再Dolphinscheduler上继续深入,我去操作系统日志找找头绪,很遗憾,在/var/log/message中也没找到什么有价值的东西;
跟踪任务调度过程
现在因为没有头绪,我决定找一个失败任务来看看执行了哪些命令,以及失败的命令是什么,这个可以在Dolphinscheduler的任务提交日志里找到相关信息:
[INFO] 2023-03-07 10:30:14.824 – [taskAppId=TASK-20230307-228-321408-1714904]:[299] – task run command:
sudo -u root sh /tmp/dolphinscheduler/exec/process/20230307/44/228/321408/1714904/228_321408_1714904.command
[INFO] 2023-03-07 10:30:14.826 – [taskAppId=TASK-20230307-228-321408-1714904]:[193] – process start, process id is: 11958
[INFO] 2023-03-07 10:30:15.562 – [taskAppId=TASK-20230307-228-321408-1714904]:[204] – process has exited, execute path:/tmp/dolphinscheduler/exec/process/20230307/44/228/321408/1714904, processId:11958 ,exitStatusCode:137
[INFO] 2023-03-07 10:30:16.533 – [taskAppId=TASK-20230307-228-321408-1714904]:[138] – -> ${SPARK_HOME2}/bin/spark-submit –name fact_pm_nr_cellcu_v2_h …..
这里其实可以看到 ,进程启动后,不到一秒的时间久退出了,并且没有任何提交的信息,正常来说,至少会有打印一些Yarn任务的提交信息,比如相关文件的上传,kerberos认证后的连接信息等,这里都没有,也就是说进程已启动就被干掉了,这基本也能排除是Dolphinscheduler自己把它干掉的情况。
接下来我把相关的执行命令粘出来,自己手动跑了一遍,任务不光能执行,还能成功:

实际上到这里问题已经陷入了僵局,直到研发哥们阴差阳错做的一个操作帮我找到了新的契机。
Sudo引发的问题
接近晚上19点的时候,我由上环境看了下,任务依旧被Kill,没啥变化貌似:
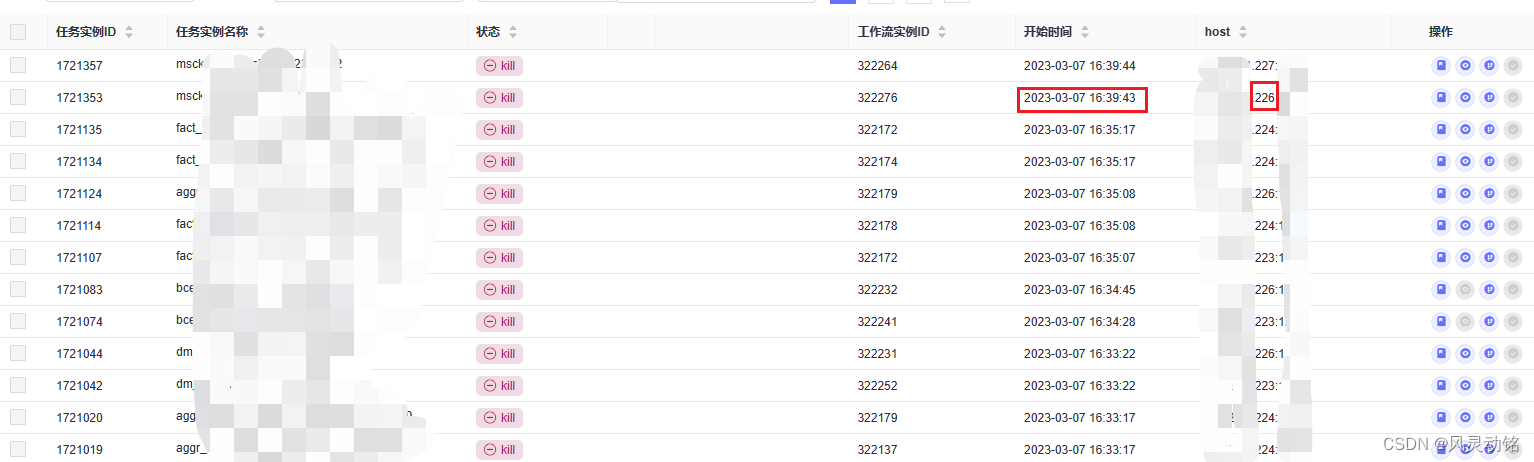
不对,我又仔细翻看了几页,在16:40以后,图中标记的226服务器就没有任务被Kill了,难道研发已经找到问题了?
本着学习的态度,去和他们团队的维护人员沟通了解情况,但他们说只改了堆内存,没有动别的东西:
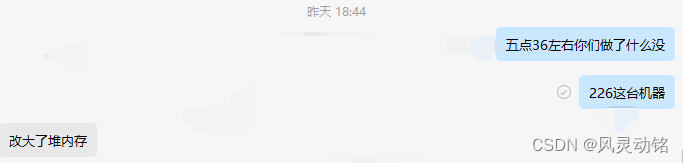
我之前已经说过这个和资源没有关系,所以我当即是认为肯定有别的东西发生改动,这个时候我想到,Dolphinscheduler在提交任务的时候,使用的是sudo -u切换root进行的,会不会是和这个有关系,于是我马上去查看了sudo的记录日志,默认一般在/var/log/secure,这下我终于找到了一些端倪,首先这是16:40以及之前的sudo记录:
Mar 7 16:40:32 sudo: dolphinscheduler : PWD=/tmp/dolphinscheduler/exec/process/20230307/43/377/322266/1721369 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/377/322266/1721369/377_322266_1721369.command
Mar 7 16:40:33 sudo: dolphinscheduler : PWD=/tmp/dolphinscheduler/exec/process/20230307/43/377/322261/1721374 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/377/322261/1721374/377_322261_1721374.command
Mar 7 16:40:34 sudo: dolphinscheduler : PWD=/tmp/dolphinscheduler/exec/process/20230307/43/377/322278/1721383 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/377/322278/1721383/377_322278_1721383.command
Mar 7 16:40:34 sudo: dolphinscheduler : PWD=/tmp/dolphinscheduler/exec/process/20230307/43/377/322255/1721380 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/377/322255/1721380/377_322255_1721380.command
这是16:40之后的sudo记录日志:
Mar 7 16:49:46 sudo: root : TTY=pts/6 ; PWD=/tmp/dolphinscheduler/exec/process/20230307/43/381/322310/1721636 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/381/322310/1721636/381_322310_1721636.command
Mar 7 16:49:46 sudo: root : TTY=pts/6 ; PWD=/tmp/dolphinscheduler/exec/process/20230307/43/381/322322/1721648 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/381/322322/1721648/381_322322_1721648.command
Mar 7 16:49:47 sudo: root : TTY=pts/6 ; PWD=/tmp/dolphinscheduler/exec/process/20230307/43/381/322312/1721638 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/381/322312/1721638/381_322312_1721638.command
Mar 7 16:49:47 sudo: root : TTY=pts/6 ; PWD=/tmp/dolphinscheduler/exec/process/20230307/43/381/322324/1721650 ; USER=root ; COMMAND=/bin/sh /tmp/dolphinscheduler/exec/process/20230307/43/381/322324/1721650/381_322324_1721650.command
执行sudo的用户变了,由原先的dolphinscheduler用户变成了root,这个区别就大了,root直接执行sudo并不会发生任何多余的事情,也就相当于直接使用root执行命令。
为了确认我的推测,我继续去核实研发人员是否改过执行用户等配置,才知道他们调整过配置以后,是通过后台启动的服务,而没有使用Ambari重启,这就导致启动用户变成了root,所以sudo用户变成了root,至此我大概确认问题是由sudo导致的,接下来就是佐证。
手动复现
主要目的是为了捕捉sudo的问题,也要尽可能模拟生产环境的操作,那么久手动写一个command的命令集:
#!/bin/sh
BASEDIR=$(cd `dirname $0`; pwd)
cd $BASEDIR
source ${DOLPHINSCHEDULER_HOME}/bin/dolphinscheduler_env.sh
kinit -k -t /etc/security/keytabs/hdfs.headless.keytab user@BIGDATA.COM || true
${SPARK_HOME2}/bin/spark-submit --version
尝试循环去运行这个命令:
for i in {1..10};do sudo -u root sh /tmp/test.command ;done
很快就看见了sudo启动的命令被Killed了:

板上钉钉,sudo确实是概率性的触发这个进程被Kill的问题。
问题分析
现在我们找到了问题的诱因,但是sudo为什么会概率性的触发这个问题呢,我接下来查了很多资料,google、Bing都没找到,最后尝试去sudo的github页去搜issues,终于找到了:
Issue-117:Sudo responds with “killed”
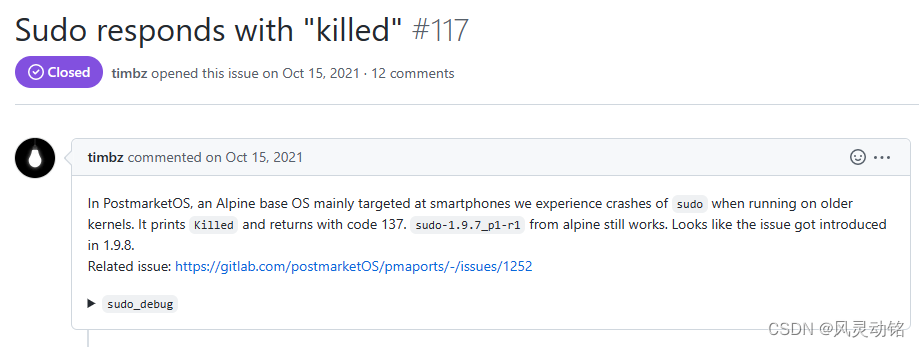
提出者遇到的现象和我们一致,甚至sudo的版本都和我们的相近,我的是1.9.6p1,根据issue的描述,这个问题是sudo在低内核版本下导致的,centos7是3.10的内核,sudo调用到的一个getentropy方法是在3.17引入的,所以使用sudo的时候概率性的会触发这个问题:

调用的位置是arc4random.c:
static void
_rs_stir(void)
{
unsigned char rnd[KEYSZ + IVSZ];
if (getentropy(rnd, sizeof rnd) == -1)
// 这里传递了SIGKILL信号
raise(SIGKILL);
if (!rs_initialized) {
rs_initialized = 1;
_rs_init(rnd, sizeof(rnd));
} else
_rs_rekey(rnd, sizeof(rnd));
explicit_bzero(rnd, sizeof(rnd)); /* discard source seed */
/* invalidate rs_buf */
rs_have = 0;
memset(rs_buf, 0, sizeof(rs_buf));
rs_count = 1600000;
}
开发者提交了一个commit来规避这个低版本内核导致的问题,commit

处理方案
现在问题已经明朗,具体的解决方案大致有3中:
- 不使用其他用户sudo,直接root,这对于很多生产环境显然不允许;
- 重新编译安装sudo命令,1.8.31-1.9.8的版本在编译的时候需要增加
ac_cv_func_getentropy=no环境变量; - 升级sudo命令到1.9.9及以上版本;
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持IT俱乐部。

