Apache Hive-通用优化-featch抓取机制 mr本地模式
Fetch抓取机制
- 功能:在执行sql的时候,能不走MapReduce程序处理就尽量不走MapReduce程序处理.
- 尽量直接去操作数据文件。
设置: hive.fetch.task.conversion= more。
--在下述3种情况下 sql不走mr程序 --全局查找 select * from student; --字段查找 select num,name from student; --limit 查找 select num,name from student limit 2;
mapreduce本地模式
- MapReduce程序除了可以提交到yarn集群分布式执行之外,还可以使用本地模拟环境运行,当然此时就不是分布式执行的程序,但是针对小文件小数据处理特别有效果。
- 用户可以通过设置hive.exec.mode.local.auto的值为true,来让Hive在适当的时候自动启动这个 优化。
功能:如果非要执行==MapReduce程序,能够本地执行的,尽量不提交yarn上执行==。
默认是关闭的。意味着只要走MapReduce就提交yarn执行。
mapreduce.framework.name = local 本地模式 mapreduce.framework.name = yarn 集群模式
Hive提供了一个参数,自动切换MapReduce程序为本地模式,如果不满足条件,就执行yarn模式。
set hive.exec.mode.local.auto = true; --3个条件必须都满足 自动切换本地模式 The total input size of the job is lower than: hive.exec.mode.local.auto.inputbytes.max (128MB by default) --数据量小于128M The total number of map-tasks is less than: hive.exec.mode.local.auto.tasks.max (4 by default) --maptask个数少于4个 The total number of reduce tasks required is 1 or 0. --reducetask个数是0 或者 1
切换Hive的执行引擎
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
如果针对Hive的调优依然无法满足你的需求 还是效率低, 尝试使用spark计算引擎 或者Tez.
Apache Hive-通用优化-join优化
在了解join优化的时候,我们需要了解一个前置知识点:map端join 和reduce端join
– reduce端join
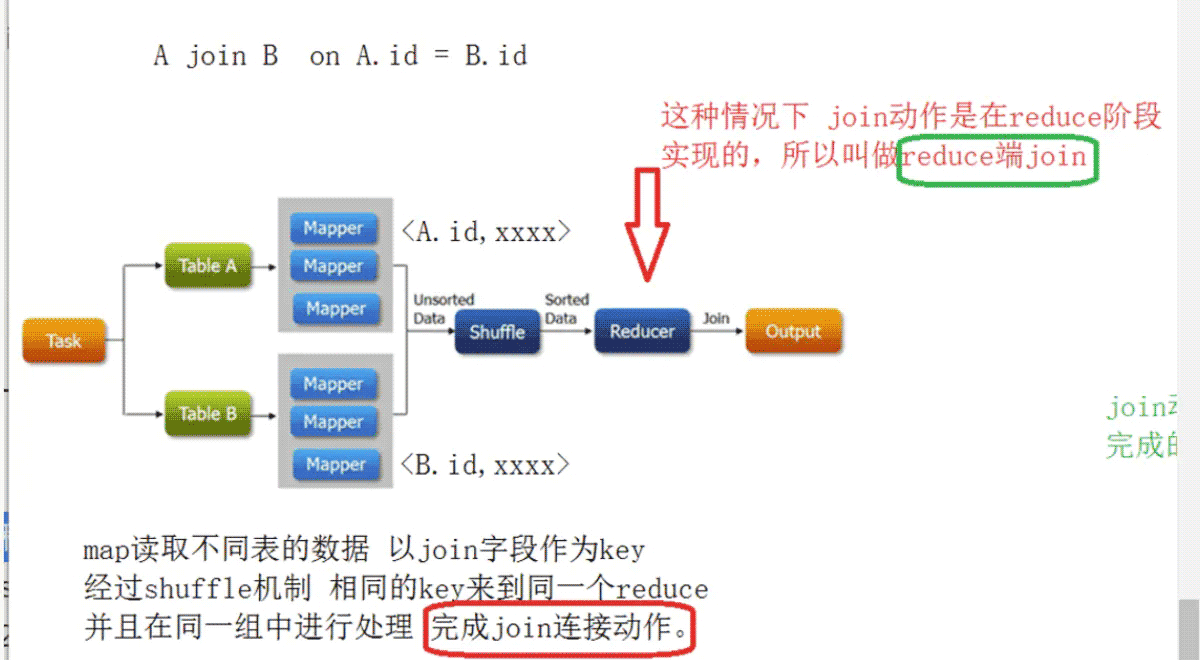
- 这种join的弊端在于map阶段没有承担太多的责任,所有的数据在经过shuffle在reduce阶段实现的,而shuffle又是影响性能的核心点.
-map端join
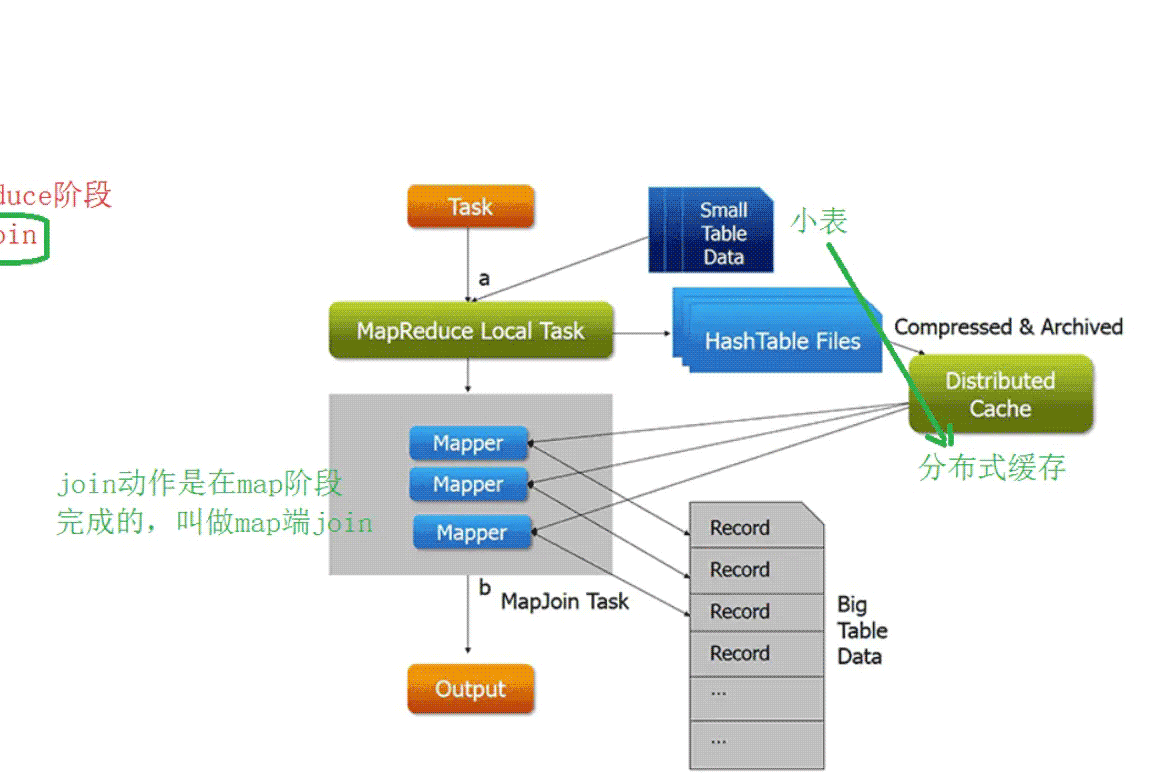
- 首先启动本地任务将join中小表数据进行分布式缓存
- 启动mr程序(只有map阶段)并行处理大数据,并且从自己的缓存中读取小表数据,进行join,结果直接输出到文件中
- 没有shuffle过程 也没有reduce过程
- 弊端:缓存太小导致表数据不能太大
reduce 端 join 优化
适合于大表Join大表
bucket join– 适合于大表Join大表
方式1:Bucktet Map Join 分桶表
语法: clustered by colName(参与join的字段)
参数: set hive.optimize.bucketmapjoin = true
要求: 分桶字段 = Join字段 ,分桶的个数相等或者成倍数,必须是在map join中
方式2:Sort Merge Bucket Join(SMB)
基于有序的数据Join
语法:clustered by colName sorted by (colName)
参数
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;
要求: 分桶字段 = Join字段 = 排序字段,分桶的个数相等或者成倍数
map 端 join 优化
- hive.auto.convert.join.noconditionaltask
hive.auto.convert.join=true Hive老版本 #如果参与的一个表大小满足条件 转换为map join hive.mapjoin.smalltable.filesize=25000000 Hive2.0之后版本 #是否启用基于输入文件的大小,将reduce join转化为Map join的优化机制。假设参与join的表(或分区)有N个,如果打开这个参数,并且有N-1个表(或分区)的大小总和小于hive.auto.convert.join.noconditionaltask.size参数指定的值,那么会直接将join转为Map join。 hive.auto.convert.join.noconditionaltask=true hive.auto.convert.join.noconditionaltask.size=512000000
Apache Hive–通用调优–数据倾斜优化
数据倾斜优化
什么是数据倾斜
描述的数据进行分布式处理 分配不平均的现象
数据倾斜的后果
某个task数据量过大 执行时间过长 导致整体job任务迟迟不结束
执行时间长 出bug及风险几率提高
霸占运算资源 迟迟不释放
通常如何发现数据倾斜
在yarn或者其他资源监控软件上 发现某个job作业 卡在某个进度迟迟不动 (注意 倒不是报错)
造成数据倾斜的原因
数据本身就倾斜
自定义分区、分组规则不合理
业务影响 造成数据短期高频波动
数据倾斜的通用解决方案
1、有钱 有预警
增加物理资源 单独处理倾斜的数据
2、没钱 没有预警
倾斜数据打散 分步执行
先将倾斜数据打散成多干份
处理的结果再最终合并
hive中数据倾斜的场景
场景一:group by 、count(distinct)
hive.map.aggr=true; map端预聚合
手动将数据随机分区 select * from table distribute by rand();
如果有数据倾斜问题 开启负载均衡
先启动第一个mr程序 把倾斜的数据随机打散分散到各个reduce中
然后第二个mr程序把上一步结果进行最终汇总
hive.groupby.skewindata=true;
场景二:join
提前过滤,将大数据变成小数据,实现Map Join
使用Bucket Join
使用Skew Join
将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现
最终将Map Join的结果和Reduce Join的结果进行Union合并
Hive中通常指的是在reduce阶段数据倾斜
解决方法
group by数据倾斜
方案一:开启Map端聚合
hive.map.aggr=true; #是否在Hive Group By 查询中使用map端聚合。 #这个设置可以将顶层的部分聚合操作放在Map阶段执行,从而减轻清洗阶段数据传输和Reduce阶段的执行时间,提升总体性能。但是指标不治本。
方案二:实现随机分区
实现随机分区 select * from table distribute by rand();
方案三:数据倾斜时==自动负载均衡==只使用group by
hive.groupby.skewindata=true; #开启该参数以后,当前程序会自动通过两个MapReduce来运行 #第一个MapReduce自动进行随机分布到Reducer中,每个Reducer做部分聚合操作,输出结果 #第二个MapReduce将上一步聚合的结果再按照业务(group by key)进行处理,保证相同的分布到一起,最终聚合得到结果
join数据倾斜
- 方案一:提前过滤,将大数据变成小数据,实现Map Join
- 方案二:使用Bucket Join
- 方案三:使用Skew Join
数据单独使用Map Join来实现
#其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免了Reduce Join中产生数据倾斜的问题 #最终将Map Join的结果和Reduce Join的结果进行Union合并 #开启运行过程中skewjoin set hive.optimize.skewjoin=true; #如果这个key的出现的次数超过这个范围 set hive.skewjoin.key=100000; #在编译时判断是否会产生数据倾斜 set hive.optimize.skewjoin.compiletime=true; set hive.optimize.union.remove=true; #如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并 set mapreduce.input.fileinputformat.input.dir.recursive=true;
Apache Hive–通用调优–MR程序task个数调整
maptask个数
- 如果是在MapReduce中 maptask是通过==逻辑切片==机制决定的。
- 但是在hive中,影响的因素很多。比如逻辑切片机制,文件是否压缩、压缩之后是否支持切割。
- 因此在==Hive中,调整MapTask的个数,直接去HDFS调整文件的大小和个数,效率较高==。
合并的大小最好=block size
如果大文件多,就调整blocl size
reducetask个数
- 如果在MapReduce中,通过代码可以直接指定 job.setNumReduceTasks(N)
- 在Hive中,reducetask个数受以下几个条件控制的
hive.exec.reducers.bytes.per.reducer=256000000
每个任务最大的 reduce 数,默认为 1009
hive.exec.reducsers.max=1009
mapreduce.job.reduces
该值默认为-1,由 hive 自己根据任务情况进行判断。–如果用户用户不设置 hive将会根据数据量或者sql需求自己评估reducetask个数。
–用户可以自己通过参数设置reducetask的个数
set mapreduce.job.reduces = N
–用户设置的不一定生效,如果用户设置的和sql执行逻辑有冲突,比如order by,在sql编译期间,hive又会将reducetask设置为合理的个数。Number of reduce tasks determined at compile time: 1
通用优化-执行计划
通过执行计划可以看出==hive接下来是如何打算执行这条sql的==。
语法格式:explain + sql语句
通用优化-并行机制,推测执行机制
并行执行机制
- 如果hivesql的底层某些stage阶段可以并行执行,就可以提高执行效率。
- 前提是==stage之间没有依赖== 并行的弊端是瞬时服务器压力变大。
参数
set hive.exec.parallel=true; --是否并行执行作业。适用于可以并行运行的 MapReduce 作业,例如在多次插入期间移动文件以插入目标 set hive.exec.parallel.thread.number=16; --最多可以并行执行多少个作业。默认为8。
Hive的严格模式
- 注意。不要和动态分区的严格模式搞混淆。
- 这里的严格模式指的是开启之后 ==hive会禁止一些用户都影响不到的错误包括效率低下的操作==,不允许运行一些有风险的查询。
设置
set hive.mapred.mode = strict --默认是严格模式 nonstrict
解释
1、如果是分区表,没有where进行分区裁剪 禁止执行
2、order by语句必须+limit限制
推测执行机制 ==建议关闭==。
- MapReduce中task的一个机制。
- 功能:
一个job底层可能有多个task执行,如果某些拖后腿的task执行慢,可能会导致最终job失败。
所谓的==推测执行机制就是通过算法找出拖后腿的task,为其启动备份的task==。
两个task同时处理一份数据,谁先处理完,谁的结果作为最终结果。
- 推测执行机制默认是开启的,但是在企业生产环境中==建议关闭==。
以上就是Apache Hive 通用调优featch抓取机制 mr本地模式的详细内容,更多关于Apache Hive 通用调优的资料请关注IT俱乐部其它相关文章!

